任务比较
图像分类,检测及分割是计算机视觉领域的三大任务。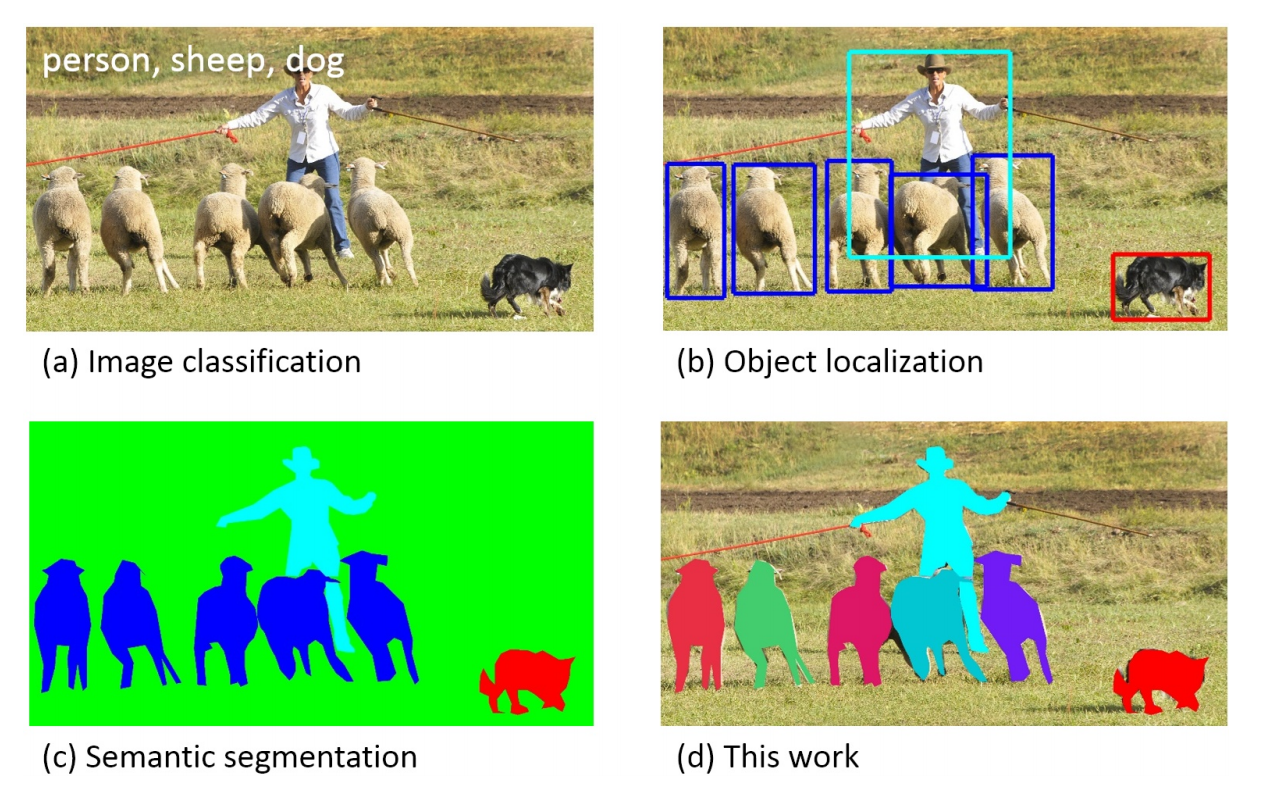
这张图清楚说明了 image classification, object detection, semantic segmentation, instance segmentation 之间的关系。摘自 COCO dataset (https://arxiv.org/pdf/1405.0312.pdf)
- 图像分类的任务是给图像分类,打标签,让机器明白图片是什么 (what),通常一张图片对应一个类别
- 目标检测的任务是检测物体的位置,并用框标记出来,让机器明白物体在哪里 (where),可以识别一张图片中的多个物体。
- 语义分割的任务是实现像素级别的分类,同一类用一种颜色表示
- 实例分割的任务是不但要进行分类,还要区别开不同的实例(这里的实例指的是具体的单个对象)
基于深度学习的目标检测算法
基于深度学习的目标检测模型主要可以分为两大类:
- One-Stage 检测算法
一步到位,直接产生物体的类别概率和位置坐标值,代表算法如 YOLO 和 SSD。
- Two-Stage 检测算法
这些算法将检测问题划分为两个阶段:第一阶段产生候选区域,第二阶段对候选区域进行分类和微调。代表算法是 R-CNN 系列算法,如 R-CNN,Fast R-CNN,Faster R-CNN 等
目标检测模型的主要性能指标是检测准确度和速度,对于准确度,目标检测要考虑物体的定位准确性,而不单单是分类准确度。一般情况下,Two-Stage 算法在准确度上有优势,而 One-Stage 算法在速度上有优势。
Google 在 2017 年开源了 TensorFlow Object Detection API,并对主流的 Faster R-CNN,R-FCN 及 SSD 三个算法在 MS COCO 数据集上的性能做了细致对比(见 Huang et al. 2017),如下图所示。
从 R-CNN 到 Mask R-CNN
R-CNN/2013
区域卷积神经网络(Regions with CNN features,简称 R-CNN),
论文:Rich feature hierarchies for accurate object detection and semantic segmentation。是利用卷积神经网络来做「目标检测」的开山之作,其意义深远不言而喻。R-CNN 的主要模型结构如下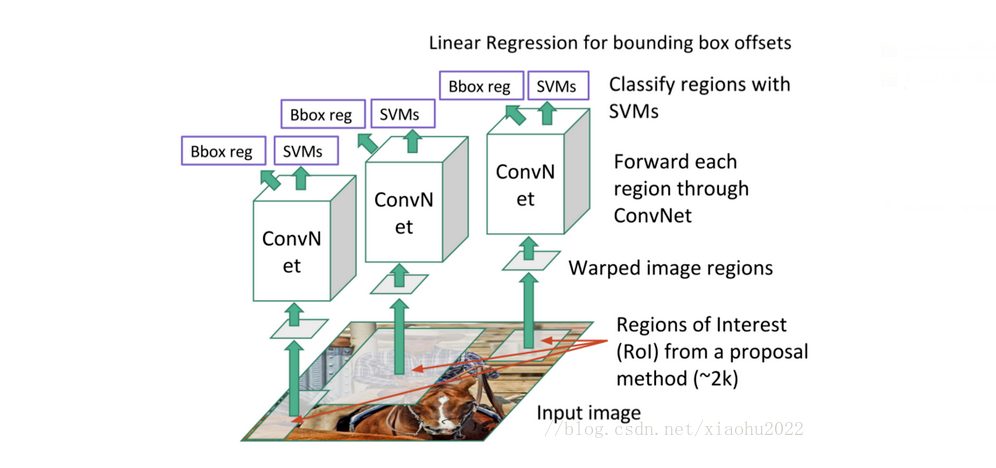
实现 R-CNN 的主要步骤分为四步;
- 首先对每张输入图像使用选择性搜索来选取多个高质量的提议区域。
- 选取一个预先训练好的卷积神经网络,去掉最后的输出层来作为特征抽取模块,得到一个特征向量。
- 每个类别训练一个 SVM 分类器,从特征向量中推断其属于该类别的概率大小。
- 为了提升定位准确性,R-CNN 最后又训练了一个边界框回归模型。
相比于传统方法,R-CNN 的优点有:
- 传统的区域选择使用滑窗,每滑一个窗口检测一次,相邻窗口信息重叠高,检测速度慢。R-CNN 使用一个启发式方法(Selective search),先生成候选区域再检测,降低信息冗余程度,从而提高检测速度。
- 使用了预先训练好的卷积神经网络来抽取特征,有效的提升了识别精度。
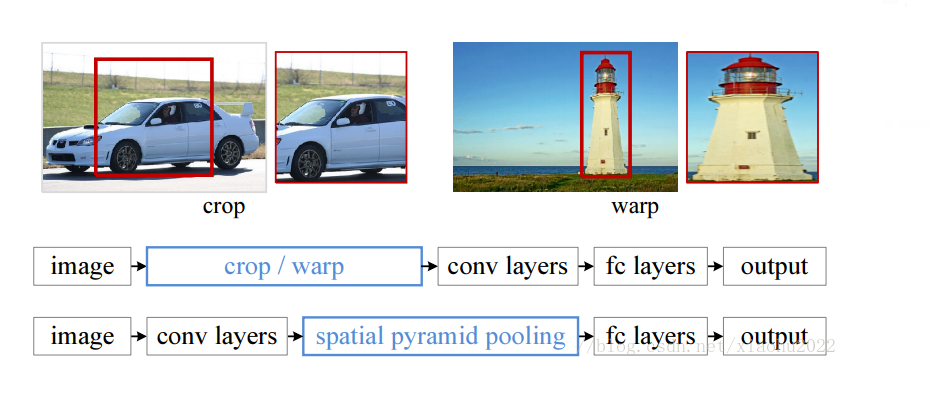
SPP-net/2014
论文 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, He et al. 2014。
R-CNN 提出后的一年,以何恺明、任少卿为首的团队提出了 SPP-net,SPP-net 中所提出的空间金字塔池化层(Spatial Pyramid Pooling Layer, SPP)可以和 R-CNN 结合在一起并提升其性能。
采用深度学习模型解决图像分类问题时,往往需要图像的大小固定(比如 224×224224×224),这并不是 CNN 层的硬性要求,主要原因在于 CNN 层提取的特征图最后要送入全连接层(如 softmax 层),对于变大小图片,CNN 层得到的特征图大小也是变化的,但是全连接层需要固定大小的输入,所以必须要将图片通过 resize, crop 或 wrap 等方式固定大小(训练和测试时都需要)。但是实际上真实的图片的大小是各种各样的,一旦固定大小可能会造成图像损失,从而影响识别精度。为了解决这个问题,SSP-net 在 CNN 层与全连接层之间插入了空间金字塔池化层来解决这个矛盾。