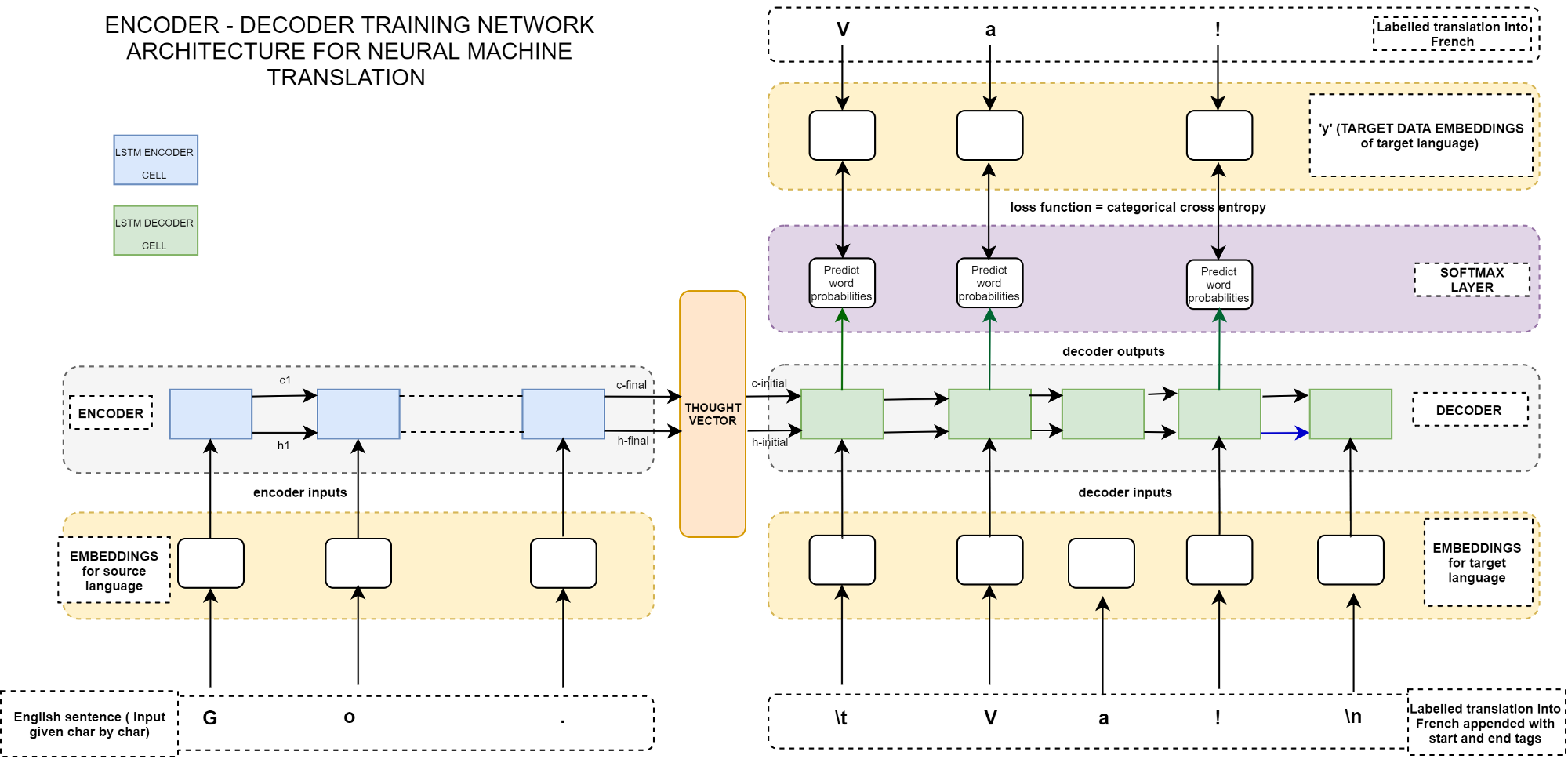
Seq2Seq 是指一般的序列到序列的转换任务,特点是输入序列和输出序列是不对齐的,比如机器翻译、自动文摘等等。
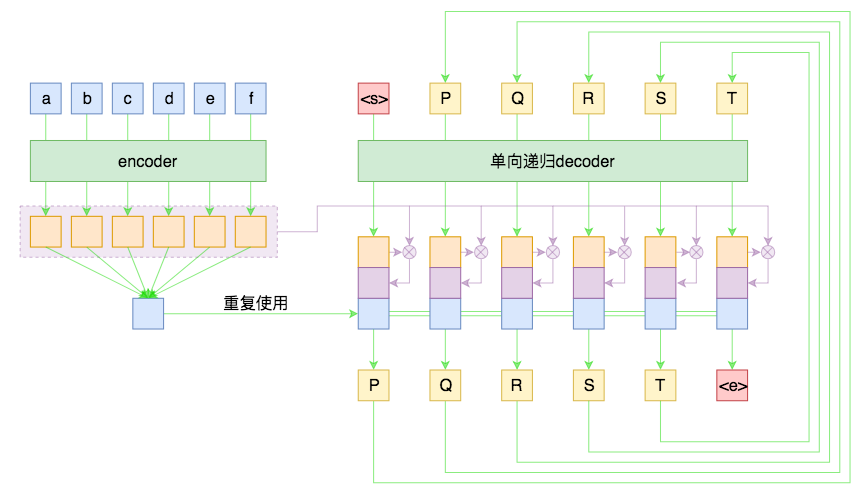
假如原句子为 X=(a,b,c,d,e,f),目标输出为 Y=(P,Q,R,S,T), 则 Seq2Seq 模型如下:
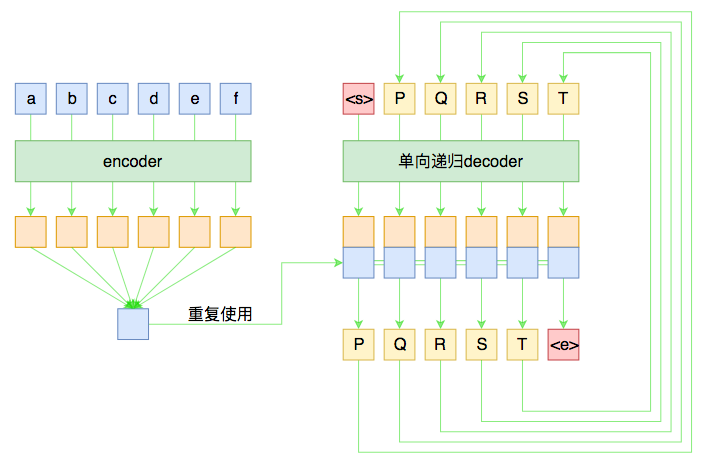
模型的工作原理如下;
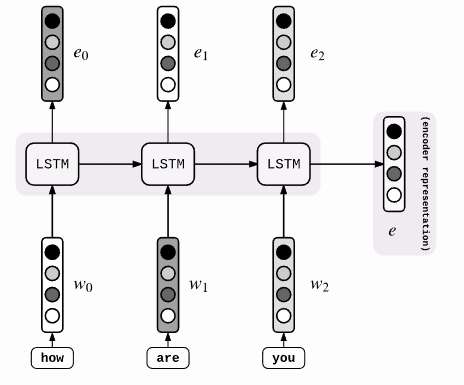
Encoder 部分首先通过 RNN 及其变种 (LSTM、GRU) 等进行编码,讲输入序列编码成一个定长向量 c,认为这个向量包含了句子的所有信息。得到 c 有多种方式,最简单的方法就是把 Encoder 的最后一个隐状态赋值给 c,还可以对最后的隐状态做一个变换得到 c,也可以对所有的隐状态做变换。
Decoder 的任务就是把这个定长向量进行解码:在给定 Target 序列的前一个字符,通过训练来预测下一个字符。
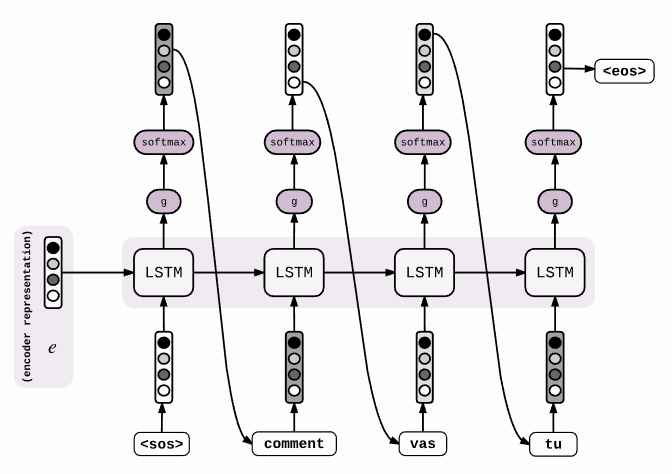
还有一种做法是将 c 当做每一步的输入:
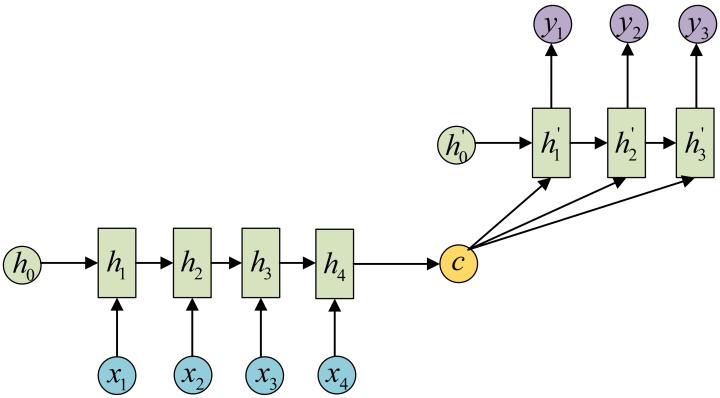
- 对于问答系统来说输入包括 Questions 和 Documents 两部分,所以要在输入进 Decoder 的时候要进行融合,可以选择 Concatenate。
Input 准备
Embedding 层
1 | from keras.models import Sequential |
Embedding 有一个参数 mask_zero, 参数的含义是当输入样本的长度不一样时候,首先对数据进行 padding 补 0,然后引入 keras 的 Masking 层,它能自动对 0 值进行过滤。
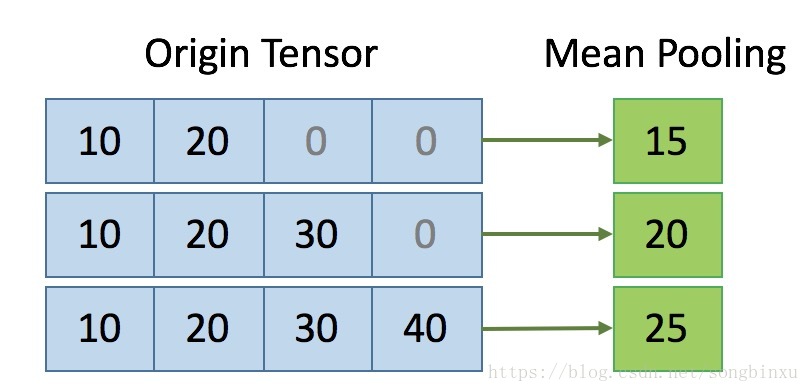
比如上面这个 3x4 大小的张量,是经过补零 padding 的。我希望做 axis=1 的 meanpooling,则第一行应该是 (10+20)/2,第二行应该是 (10+20+30)/3,第三行应该是 (10+20+30+40)/4。这个时候应该是 mask_zero=True 的,过滤掉 0 值。
Dropout
SpatialDropout1D 和 Dropout 的比较。
Encoder 层
1 | keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0) |
在 Keras 所有的 RNN 中,包括 simpleRNN, LSTM, GRU 等等,输入输出数据格式如下:

例如这样一个数据,总共 100 条句子,每个句子 20 个词,每个词都由一个 80 维的向量表示,输入数据的大小应当是(100, 20, 80)。因此各个维度的含义如下 :
- samples 为样本数目
- timesteps 为句子长度(padding 后的 max_len)
- input_dim 为数据的维度
下面的三个代码写法是等价的。
1 | #model.add(LSTM(input_dim=1, output_dim=6,input_length=10, return_sequences=True)) |
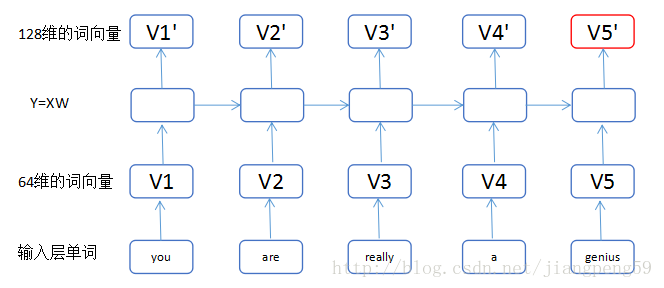
return_sequences 的含义是每个 LSTM 单元是否返回输出,我们可以通过上面的图来解释 return_sequences:
- return_sequences=True,我们可以获得 5 个 128 维的词向量 V1’..V5’
- return_sequences=False,只输出最后一个红色的词向量
1 | model = Sequential() |
Concatenate
作用是把两个张量在某个维度级联起来。参考下面这个链接。https://nbviewer.jupyter.org/github/anhhh11/DeepLearning/blob/master/Concanate_two_layer_keras.ipynb
TimeDistributed
考虑一批 32 个样本,其中每个样本是一个由 16 个维度组成的 10 个向量的序列。该层的批输入形状然后 (32, 10, 16)。TimeDistributed 层的作用就是把 Dense 层应用到这 10 个具体的向量上,对每一个向量进行了一个 Dense 操作,假设是下面这段代码:
1 | model = Sequential() |
输出还是 10 个向量,但是输出的维度由 16 变成了 8,也就是(32,10,8)。
LSTM 模型分析
下图是 LSTM 的一个典型内部示意图,有三个门:输入门、输出门和遗忘门。
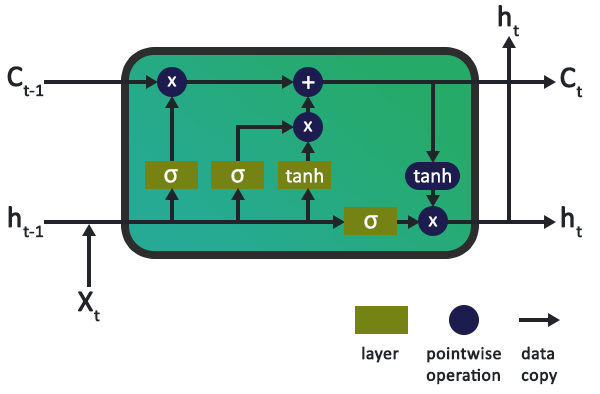
| 符号 | 含义 | 符号 | 含义 |
|---|---|---|---|
| C(t-1) | 上一个 LSTM 单元的记忆 | C(t) | 新更新的记忆 |
| h(t-1) | 上一个 LSTM 单元的输出 | h(t) | 当前输出 |
| σ | Sigmoid 层 | X | 信息 |
| tanh | tanh 层 | + | 增加信息 |
Attention
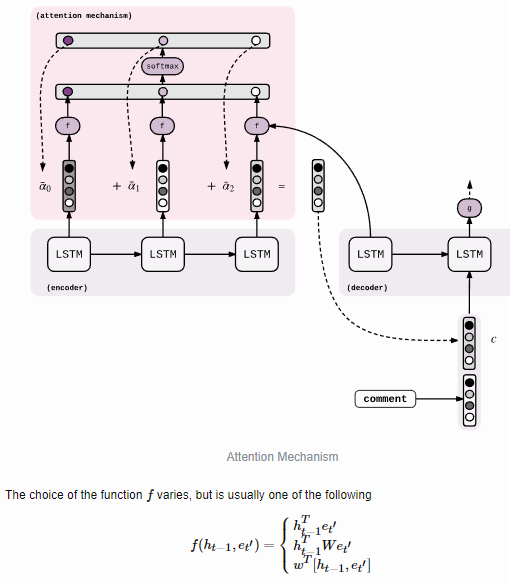
Attention 的思想是:每一步解码时,不仅仅要结合 encoder 编码出来的固定大小的向量(通读全文),还要往回查阅原来的每一个字词(精读局部),两者配合来决定当前步的输出。
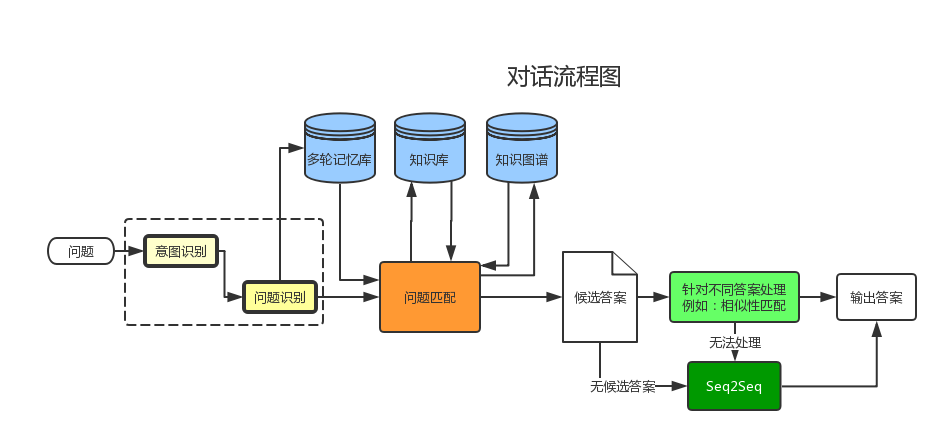
对话系统
训练技巧
1. 刚开始内存跑满了,分析了一下原因主要是词典太大,所以对词典进行了词频分析,选出指定大小的常用词,其他低频词语用 
2. 采用 pickle 序列化中间结果,一般来说生成的二进制数据比较大,但是能大大加快读取速度。
3. 代码结构函数化,使用面向对象的方式编程,增强代码的可复用性。
4. 通过小批量数据验证代码的正确性,方便程序的调试。
5. 使用 Pycharm 远程连接服务器来跑代码,结合计算资源和开发工具,提升开发效率。
存在的问题
1. 没有使用 batch 来小批量输入数据。
2. 训练和预测使用的 decoder 结果不同,编写循环的预测 decoder。
3. 前端的 word2vec 词向量和最新的 ElMo 模型的对比实验。
4. 对比不同的 decoder 结构对模型的影响程度。
5. 了解 Attention 原理,在模型中加入 Attention 来提高准确率。

