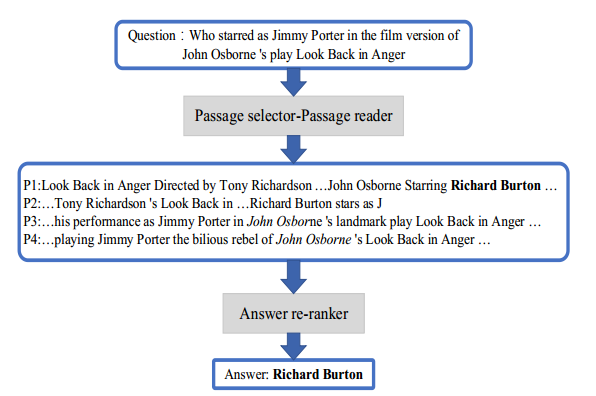
最大匹配算法
基于词典的双向匹配算法的中文分词算法的实现。
例子:[我们经常有意见分歧]
词典:[我们,经常,有,有意见,意见,分歧]
前向最大匹配
先设定扫描的窗口大小 maxLen(最好是字典最长的单词长度),从左向右取待切分汉语句的 maxLen 个字符作为匹配字段。查找词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来,并将窗口向右移动这个单词的长度。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
后向最大匹配
该算法是正向的逆向算法,区别是窗口是从后向左扫描,若匹配不成功,则去掉第一个字符,重复上述的匹配步骤。
双向最大匹配
双向最大匹配法是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。定义的匹配规则如下:
- 如果正反向匹配算法得到的结果相同,我们则认为分词正确,返回任意一个结果即可。
- 如果正反向匹配算法得到的结果不同,则考虑单字词、非字典词、总词数数量的数量,三者的数量越少,认为分词的效果越好。我们设定一个惩罚分数(score_fmm /score_bmm = 0),例如:正向匹配中单字词数量多于反向匹配,则正向匹配的分值 score_fmm += 1。其他两个条件相同。可以根据实际的分词效果调整惩罚分数的大小,但由于没有正确分词的数据,因此惩罚分数都设为 1。最后比较惩罚分数,返回较小的匹配结果。