论文 1
《 3R: Reading - Ranking - Recognizing for Multi-Passage Reading Comprehension》
简介
ITAIC 2019 的一篇文章。本文主要用来解决的是 Multi-passage reading comprehension 问题。
模型结构
文章提出了阅读 - 排序 - 识别三段式模型,分别为:
- 段落提取模块:提取所有与问题相关的段落
- 阅读理解模块:阅读每个提取出来的相关段落,抽取出候选答案。其中阅读理解模块基于 BERT。
- 答案排序模块:提出两种答案排序策略,分别是 question-to-answer verify 和 answer-to-answer verify
这三个模块完成后,还增加了 no answer recognition section,来判断是否有问题的答案。
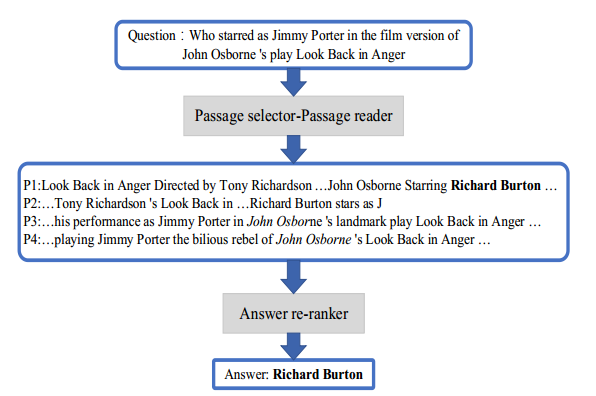
段落提取模块
论文 2
《Joint Training of Candidate Extraction and Answer Selection for Reading Comprehension》
简介
百度的一篇文章,Accepted by ACL 2018。论文把 RC 分为两个阶段,第一阶段产生候选答案集合,第二阶段进行答案选择即答案评分。整体模型结构如下:

产生候选答案的模型

进行答案选择的模型

论文 3
《Retrieve-and-Read: Multi-task Learning of Information Retrieval and Reading Comprehension》
简介
百度的一篇文章, Accepted as a full paper at CIKM 2018。本文把基于文档的阅读理解系统称之为 machine reading at scale (MRS) Task(但是不知道是不是这篇文章首先提出的这个概念)。任务的具体描述如下:
given a question, a system retrieves passages relevant to the question from a corpus and then extracts the answer span from the retrieved passages.
其实是 IR 和 RC 结合的任务,这种类型任务的数据集有 DrQA 等,来自下面这篇陈丹奇的论文:
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to Answer Open-Domain Questions. In ACL. 1870–1879.
但是这篇论文有个缺点就是第一步检索或者叫召回文档的时候精确率不高(500 万文档中召回 Top5),一般召回的文档是包含问题里面的词语的,但是由于召回的文档不全是和问题相关的。
这篇文章主要关注 IR 和 MC 的关系。论文指出 RC 找出答案范围的能力会提升 IR 区分段落和问题是否相关的能力。
- 是否可以通过训练好的 RC 模型提升 IR 的能力?
不行,因为训练的 RC 模型使用和问题强相关的段落训练的,并不能预测与问题无关的段落上没有答案。(这个地方的理解有点问题,是在说模型的泛化能力有问题?我倾向于是说 SQUAD1.1 的任务上面都是有答案的,所有模型架构不支持无答案的回答)
本论文谈到了 3R 那篇论文提出了联合训练 IR 和 MC 任务。
具体实现
本文提出了一种监督的多任务学习方法,即共享模型隐藏层参数,然后最小化 RC 和 IR 的 Joint Loss。模型总体结构如下: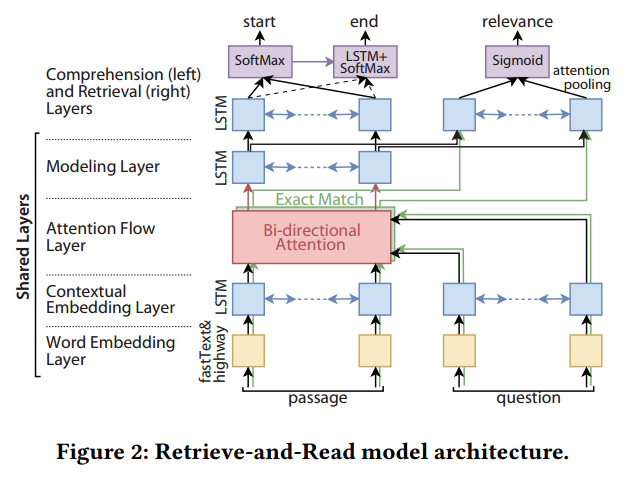
从模型架构上看,如果是单任务的 RC,那么模型和 BiDAF 一样。
接着论文介绍了模型的各个层的设计,我们重点关注一下 Retrieval layer,其实就是 BIDAF 的输出接单层 LSTM,然后做 Attention Pooling, 最后 Sigmoid 输出,输出代表问题和文档的相关程度。
接着介绍了如何多任务学习的另一个重要内容就是多任务学习的损失函数设计:
然后介绍模型的实际工作原理。来了一个 Q,和文档拼接输入到这个模型中,由模型给出答案和 IR 评分,根据 IR 评分给出最后的答案排序。但是这里有个大问题就是当海量文档的时候不适用,论文提出了改进的方案,参考的这一篇论文:《High accuracy retrieval with multiple nested ranker》,稍后读一下。
结果
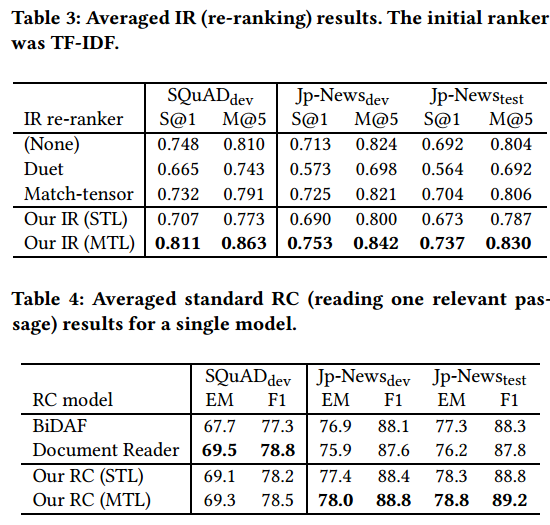
主要在 SQuAD 上测试的。作者回复了几个问题。
- 消融实验,分别比较了 IR 和 MC 的效果
论文 4
《Denoising Distantly Supervised Open-Domain Question Answering》
简介
清华大学 ACL2018 的论文。分为两个部分:Paragraph Selector 和 Paragraph Reader。
监督的开放域问答(DS-QA)的目的是在未标记文本的集合中找到答案。 现有的 DS-QA 模型通常从大型语料库中检索相关段落并运用阅读理解技术从最相关的段落中提取答案。 他们忽略了其他段落中包含的丰富信息。
此外,远程监管数据不可避免地会伴随着错误的标签问题,而这些嘈杂的数据将大大降低 DS-QA 的性能。 为了解决这些问题,我们提出了一种新颖的 DS-QA 模型,该模型采用段落选择器过滤掉那些嘈杂的段落,并使用段落阅读器从那些去噪的段落中提取正确答案。 实际数据集上的实验结果表明,与所有基线相比,我们的模型可以从嘈杂的数据中捕获有用的信息,并在 DS-QA 上取得重大改进。 论文代码:https://github.com/thunlp/OpenQA

论文 5
《Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering》
简介
Published as a conference paper at ICLR 2018。回答开放域问题的最新流行方法是首先搜索与问题相关的段落,然后应用阅读理解模型来提取答案。 现有方法通常从单个段落中独立提取答案。 但是,有些问题需要来自不同来源的综合证据才能正确回答。 在本文中,我们提出了两个模型,它们利用多个段落来产生答案。 两者都使用答案排序方法,该方法对由现有的最新质量检查模型生成的答案候选者进行重新排序。 我们提出两种方法,即基于强度的重新排名和基于覆盖率的重新排名,以利用来自不同段落的汇总证据来更好地确定答案。 我们的模型在三个公共开放域 QA 数据集:Quasar-T,SearchQA 和 TriviaQA 的开放域版本上取得了最新的成果,与前两个数据集相比,改进了大约 8 个百分点。

论文 6
《Quasar: Datasets for Question Answering by Search and Reading》
简介
这篇文章是一个数据集。我们提出了两个新的大规模数据集,旨在评估旨在理解自然语言查询并从大型文本语料库中提取其答案的系统。 Quasar-S 数据集由 37000 个完形填空组成,这些 queries 是根据流行网站 Stack Overflow 上的软件实体标签的定义构造的。网站上的帖子和评论用作回答完形填空问题的背景语料库。 Quasar-T 数据集包含 43000 个开放域琐事问题以及从各种 Internet 来源获得的答案。 ClueWeb09 用作提取这些答案的背景语料库。我们将这些数据集摆在对事实相关问题的两个相关子任务的挑战上:(1)搜索包含查询正确答案的相关文本,以及(2)读取检索到的文本以回答查询。我们还描述了一种检索系统,用于从给出查询的语料库中提取相关的句子和文档,并将其包含在发布版本中,以供研究人员仅关注(3)我们评估了这两个数据集上的几个基线,从简单的启发式方法到强大的神经模型,都表明,对于 Quasar-S 和 Quasar-T,这些基线分别落后于人类性能 16.4%和 32.1%。数据集地址 https://github.com/bdhingra/quasar。
论文 7
《S-Net: From Answer Extraction to Answer Generation for Machine Reading Comprehension》
简介

论文 8
《Selecting Paragraphs to Answer Questions for Multi-passage Machine Reading Comprehension》
简介
focus on 单问题多段落的段落排序


