课程介绍

B 站视频:https://www.bilibili.com/video/av67224054
Lecture 1:引言
- 2012 年 Alnet 在 ImageNet 上错误率大幅度下降
- 2016 年 3 月 Alphgo 战胜人类围棋高手
- 机器学习设计概率论,凸分析,统计学等
- 数据挖掘主要使用机器学习进行分析数据,并使用数据库来管理数据
- 1980 年,在 CMU 召开了第一次 ICML 会议,标志着机器学习的诞生
五本推荐的书:
- 统计学习方法
- 深度学习(花书)
- 模式识别与机器学习(PRML)
- 机器学习实战
- 机器学习(西瓜书)
Lecture 2:机器学习基本概念
监督学习和假设空间
监督学习目的是学习一个由输入到输出的映射,称为模型,模型集合就是假设空间。
学习三要素
三要素:模型 + 策略 + 最优化方法
策略
详细数据推导可参考这篇文章
- 损失函数:定义在单个训练样本的损失,也就是就算一个样本的损失
- 代价函数:定义在整个训练集整体的误差描述,也就是所有样本的误差的总和,也就是损失函数的总和。
- 经验风险:代价函数的平均,定义在训练集上,是局部的,是现实的,可求的。
- 期望风险:表示的是决策函数对所有的样本的预测能力的大小,是全局的,是理想化的,不可求的。
- 经验风险最小化:极大似然估计是经验风险最小化的一个例子,当模型是条件概率分布,损失函数是对数损失函数的时候,经验风险最小化等价于极大似然估计。样本容量很小,经验风险最小化的效果未必好,会产生过拟合。
- 结构风险最小化:经验风险+正则化项表示结构风险,是防止过拟合的策略。。贝叶斯的最大后验概率估计就是结构风险最小化的例子。当模型是条件概率分布,损失函数是对数损失函数、模型复杂度由模型的先验概率表示时,结构风险最小化等价于最大后验概率估计。
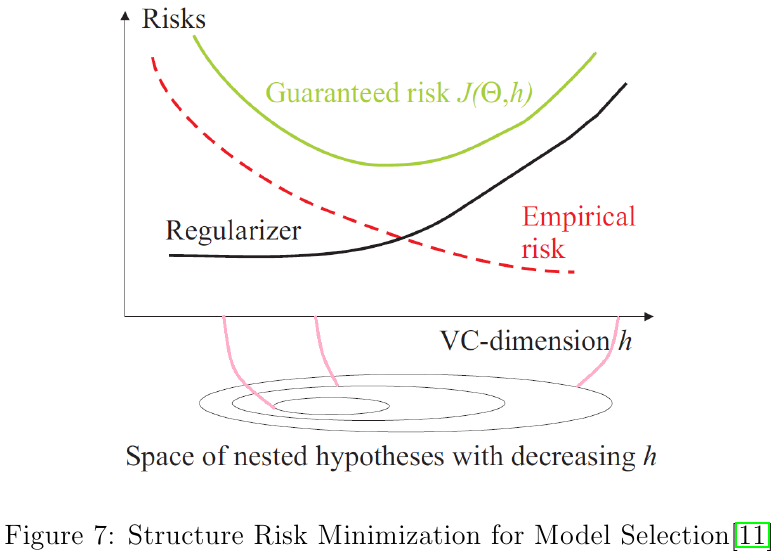
奥卡姆剃刀定理
定理:简单的是最好的
没有免费的午餐定理
定理:没有一种机器学习算法是适用于所有情况的。
这个定理本质上就是告诉我们不要奢望能找到一种算法对所有问题都适用。注意,这个定理有个前提:“对于所有机器学习问题,且所有问题同等重要”。而我们实际情况不是这样,我们在实际中往往更关心的是一个特定的机器学习问题,对于特定的问题,特定的机器学习算法效果自然比瞎猜更好。
训练误差和测试误差
机器学习模型在训练数据集上表现出的误差叫做训练误差,在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差。
统计学习理论的一个假设是:训练数据集和测试数据集里的每一个数据样本都是从同一个概率分布中相互独立地生成出的(独立同分布假设)。
一个重要结论是:训练误差的降低不一定意味着泛化误差的降低。机器学习既需要降低训练误差,又需要降低泛化误差。
过拟合
欠拟合:模型无法得到较低的训练误差
过拟合:机器学习模型的训练误差远小于其在测试数据集上的误差。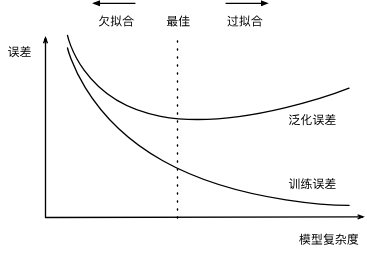
正则化
虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。这里介绍过拟合问题的常用方法:正则化。
L1 和 L2 正则化在神经网络中的运用和其他机器学习方法一样,通过约束权重的 L1 范数或者 L2 范数,对模型的复杂度进行惩罚,来减小模型在训练数据集上的过拟合问题。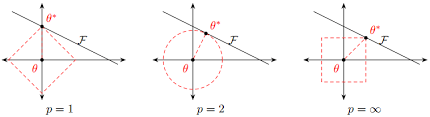
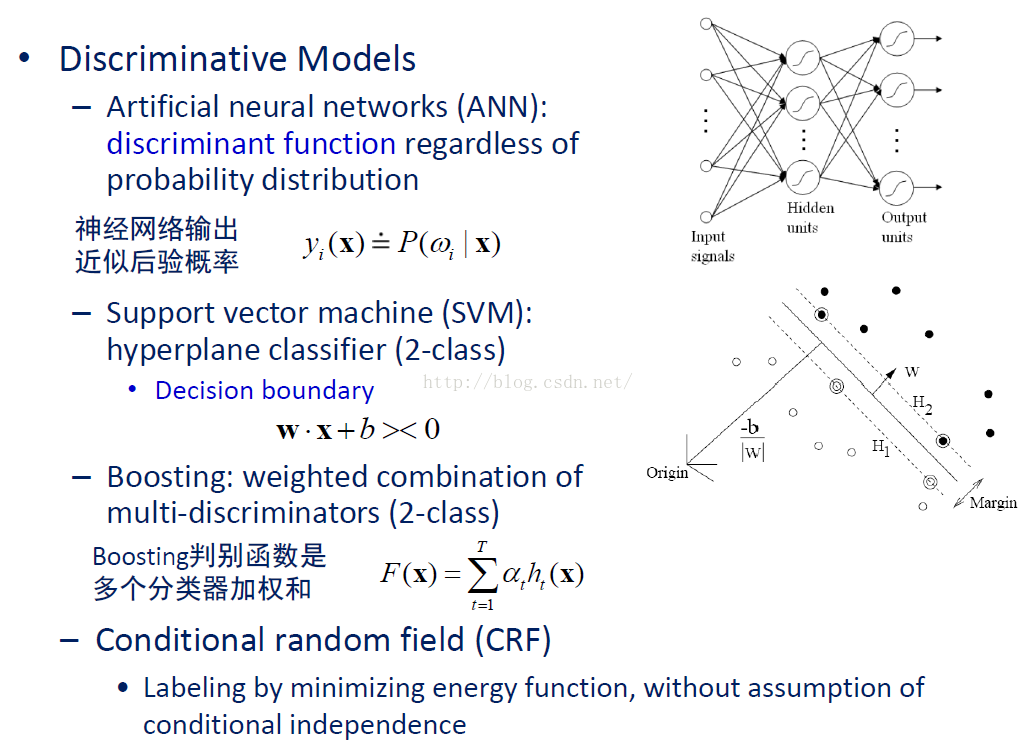
生成模型和判别模型
判别式模型举例:要确定一个羊是山羊还是绵羊,用判别模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成式模型举例:利用生成模型是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,在放到绵羊模型中看概率是多少,哪个大就是哪个。
上面例子说明,判别式模型是根据一只羊的特征可以直接给出这只羊的概率(比如 logistic regression,这概率大于 0.5 时则为正例,否则为反例),而生成式模型是要都试一试,最大的概率的那个就是最后结果。
比较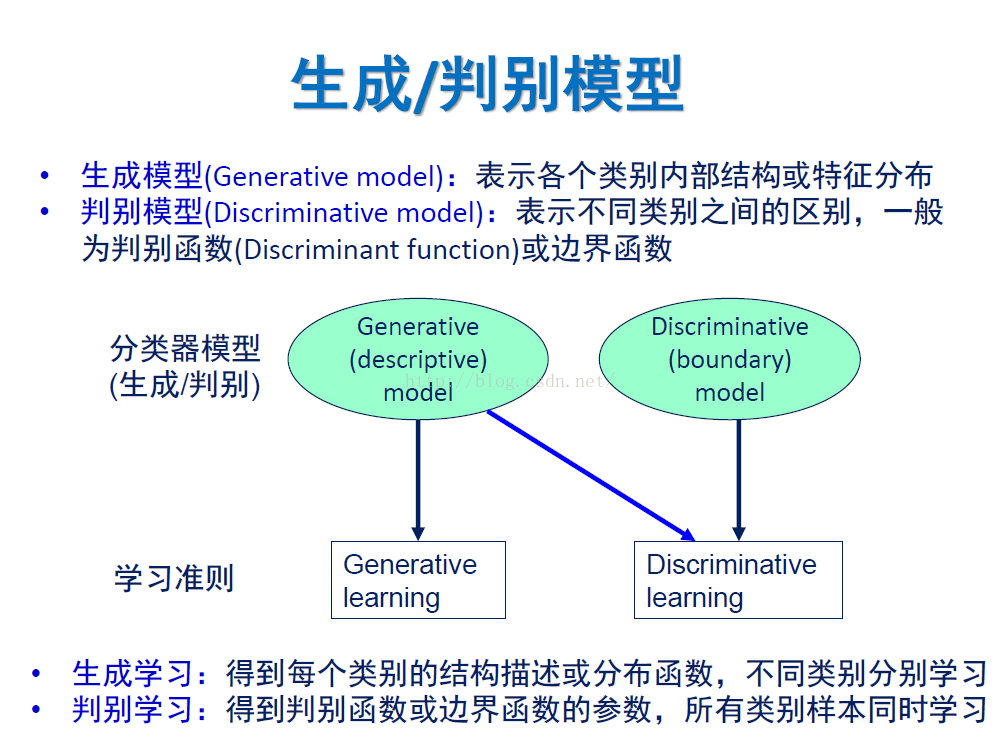
生成模型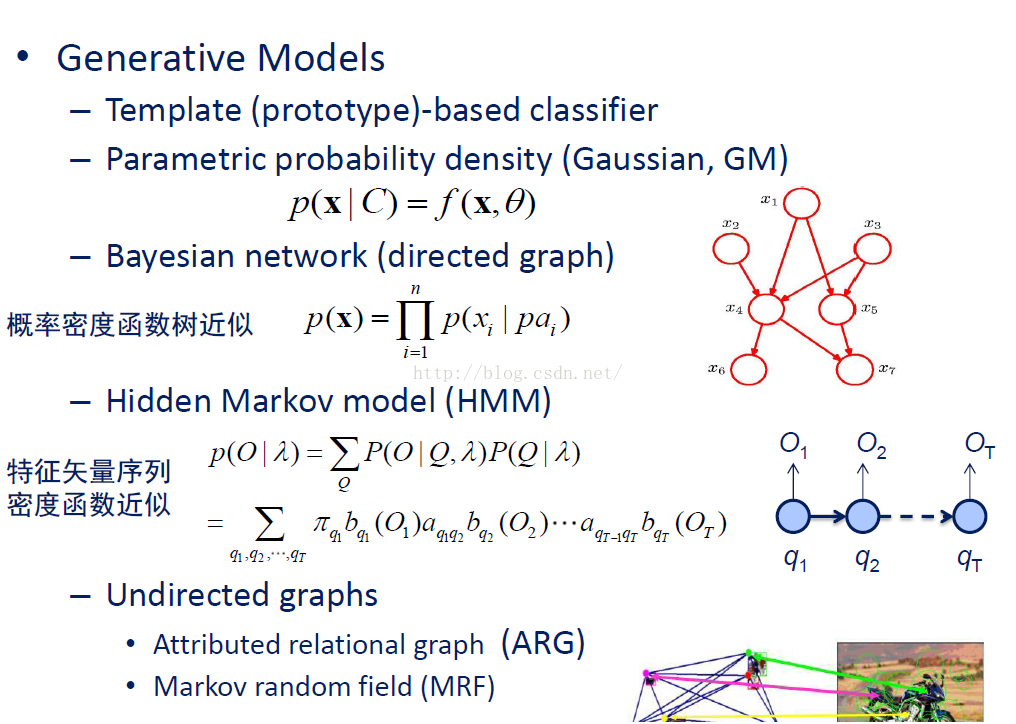
判别模型