
最大似然估计和最大后验估计

图片来自网站
- 频率学派 - Frequentist - Maximum Likelihood Estimation (MLE,最大似然估计)
- 贝叶斯学派 - Bayesian - Maximum A Posteriori (MAP,最大后验估计)
生成模型和判别模型

- 生成模型可以产生数据,判别模型只能根据数据做判断。
- 生成模型的指导思想是贝叶斯,判别模型的指导思想是频率学派
朴素贝叶斯
算法
K 近邻分类
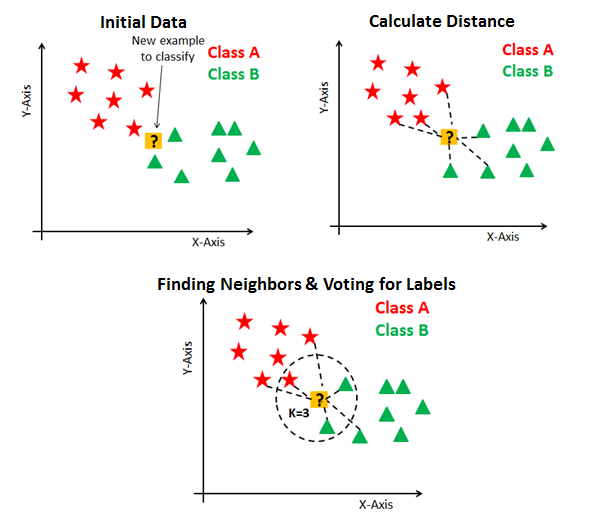
核心思想:基于距离的模板匹配
KNN 是一种判别模型,即支持分类问题,也支持回归问题,是一种非线性模型,天然支持多分类,而且没有训练过程。
从香农说起
我在大学上量子物理的时候,觉得这门课公式繁多,一度不愿意去学习。直到后来我看到近代量子物理的发展简史,才感受到其中的美妙。那是一种人文与科学的交织,我深深陶醉其中,也对量子物理兴趣大发。我觉得深度学习也是这样,我们应该了解公式背后的历史。跟随着那些有趣灵魂的脚步,才会明白是这一切将去往何方。

香农(1916 年 4 月 30 日-2001 年 2 月 26 日),美国数学家、电子工程师和密码学家,被誉为信息论的创始人。1948 年,香农发表了划时代的论文 —— 通信的数学原理,在这部著作中,他提出了比特数据,证明了信息是可以被量化的,并阐述了如何在保证准确率的前提下用数字编码对信息进行压缩和传输。
关于 AI 创业
今天看到一个网站,一个 AI,看了一下是世纪佳缘做的。说实话,做的相当没有水平,完全是照抄 RASA 的,我甚至觉得我也可以做一个更好的出来,甚至由此萌发了想创业的想法。
腾讯广告部门一面 - 自然语言处理方向
今天上午 10 点突然接到面试的电话,面完之后感觉不怎么好,还是总结一下吧。
Pool 的作用
池化层是一个采样的过程。

Word2Vec 的损失函数
ElMo 的损失函数
预训练部分
在 EMLo 中,他们使用的是一个双向的 LSTM 语言模型,由一个前向和一个后向语言
模型构成,目标函数就是取这两个方向语言模型的最大似然。
前向部分
反向部分
合起来部分如下,也就是损失函数
微调部分(用于下游任务)
在进行有监督的 NLP 任务时,可以将 ELMo 直接当做特征拼接到具体任务模型的
词向量输入,具体来说就是把这个双向语言模型的每一中间层进行一个求和得到动态的词向量表示。
提取词向量的过程如下:对于第 K 个 Token, 使用 L 层的双向 ELMo 可以得到的表示如下:
对于下游任务来说,得到表示就是各层双向 LSTM 的表示的加权和
快速排序的复杂度计算
Network In Network
论文 Network In Network(Min Lin, ICLR2014).
论文的主要贡献
- 采用 mlpcon 的结构来代替 traditional 卷积层
- 采用 global average pooling 层代替卷积神经网络最后的全连接层