论文 Network In Network(Min Lin, ICLR2014).
论文的主要贡献
- 采用 mlpcon 的结构来代替 traditional 卷积层
- 采用 global average pooling 层代替卷积神经网络最后的全连接层
NIN
传统 cnn 网络中的卷积层其实就是用线性滤波器对图像进行内积运算,在每个局部输出后面跟着一个非线性的激活函数,最终得到的叫作特征图。而这种卷积滤波器是一种广义线性模型。所以用 CNN 进行特征提取时,其实就隐含地假设了特征是线性可分的,可实际问题往往是难以线性可分的。
什么样的模型抽象水平更高呢。当然是比线性模型更有表达能力的非线性函数近似器了(比如 MLP 多层感知神经网络)。
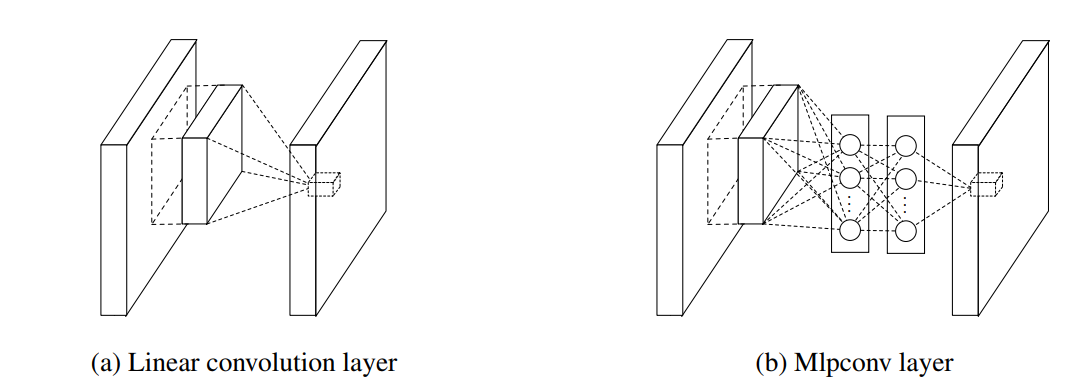
MLP 的优点:
- 非常有效的通用函数近似器
- 可用 BP 算法训练,可以完美地融合进 CNN
- 其本身也是一种深度模型,可以特征再利用
NIN 和 1x1 卷积的关系
因为 NIN 中的 MLP 层可以用两层 1×1 卷积核来代替,比如当前这一层是 54×54×96 的图像层,然后过一个 1×1×96 的卷积核,还是一个 54×54×96 的卷积层,然后再过一个 1×1×96 的卷积核,还是一个 54×54×96 的卷积层。 但是这样但看最开始那个 96 个特征层的图像同一个位置不同层之间的像素点,相当于过了一个 96×96×96 的 MLP 网络 。
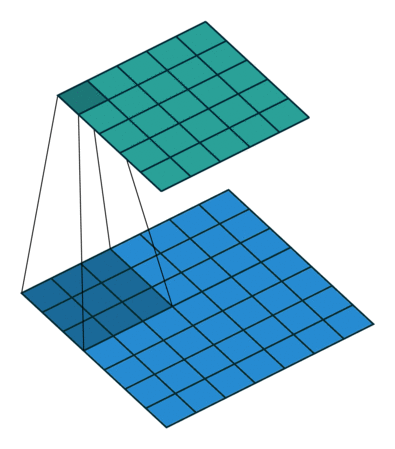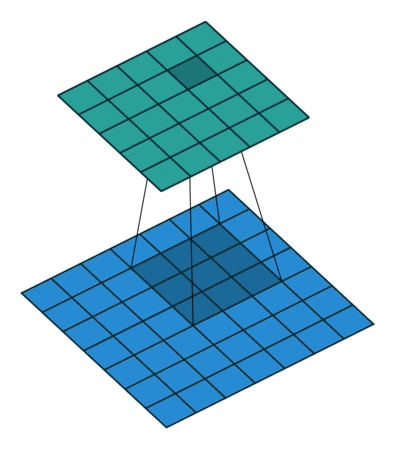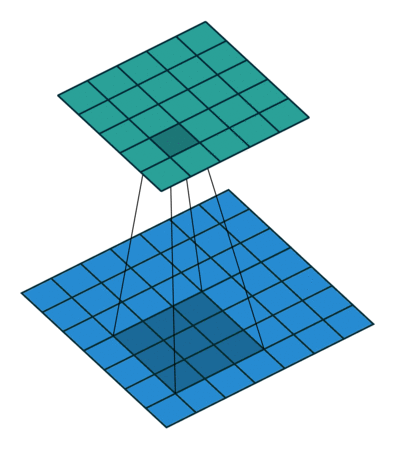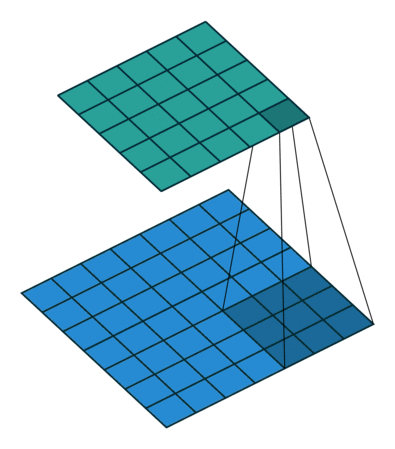
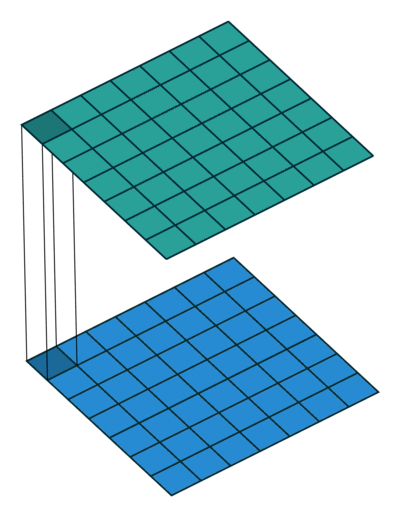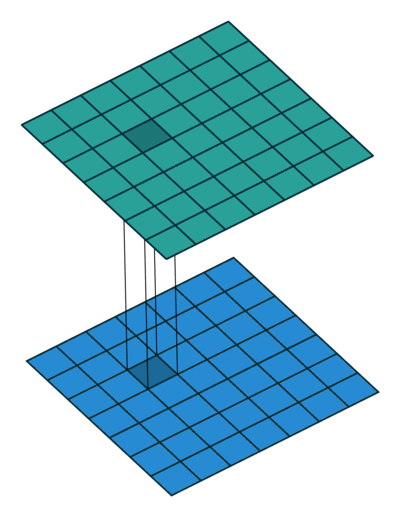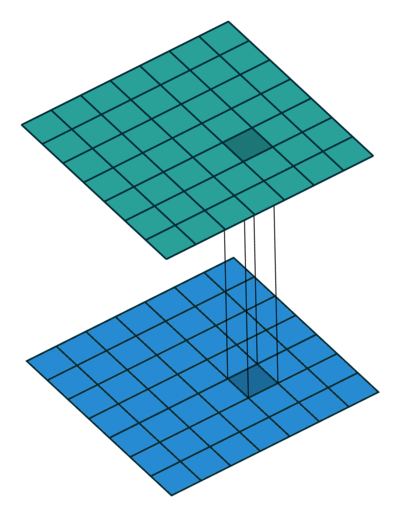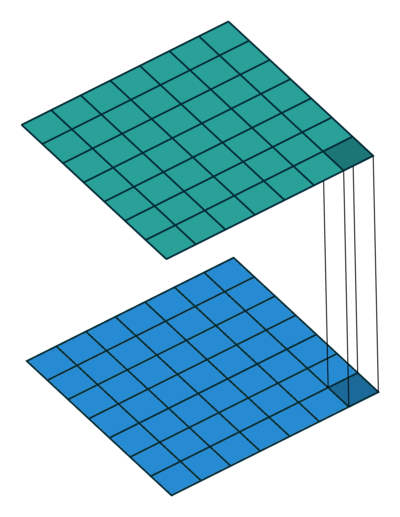
1x1 卷积
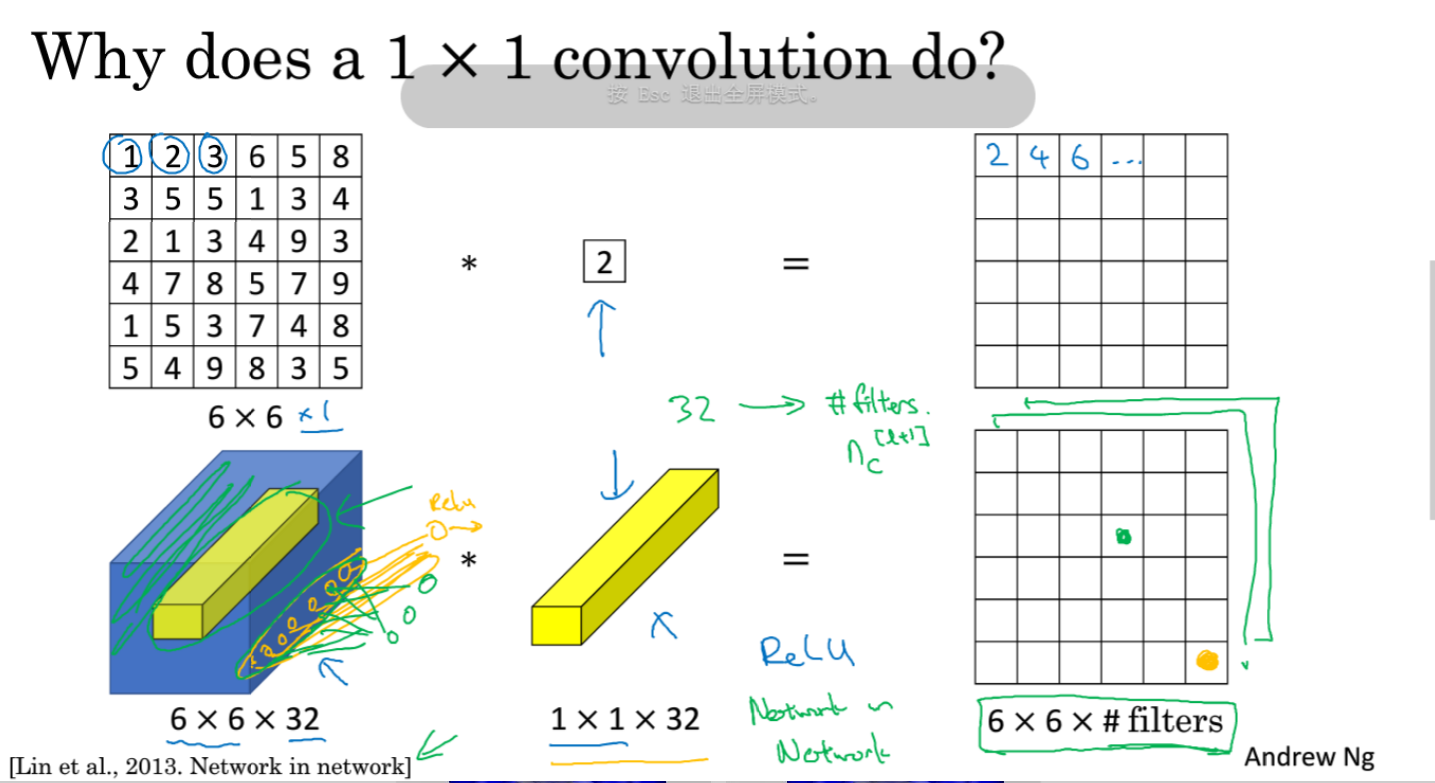
如果卷积的输出输入都只是一个平面,那么 1x1 卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。 但卷积的输出输入是长方体,所以 1x1 卷积实际上是对每个像素点,在不同的 channels 上进行线性组合(信息整合),且保留了图片的原有平面结构,调控 depth,从而完成升维或降维的功能。
比如 3x3 卷积或者 5x5 卷积在几百个 filter 的卷积层上做卷积操作时相当耗时,所以 1x1 卷积在 3x3 卷积或者 5x5 卷积计算之前先降低维度。比如,一张 500×500 且厚度 depth 为 100 的图片在 20 个 filter 上做 1×1 的卷积,那么结果的大小为 500×500×20。然后再进行 3x3 卷积或者 5x5 卷积就可以了。
总结一下:
- 相当于输入每个元素对应的所有通道分别进行了全连接运算,输出即为 filters 的数量。
- 池化层可以压缩高度和宽度,1×1 卷积可以压缩或增加通道数。
- 加入非线性。卷积层之后经过激励层,1×1 的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力
| 3x3 卷积 | 1x1 卷积 |
|---|---|
 |
 |
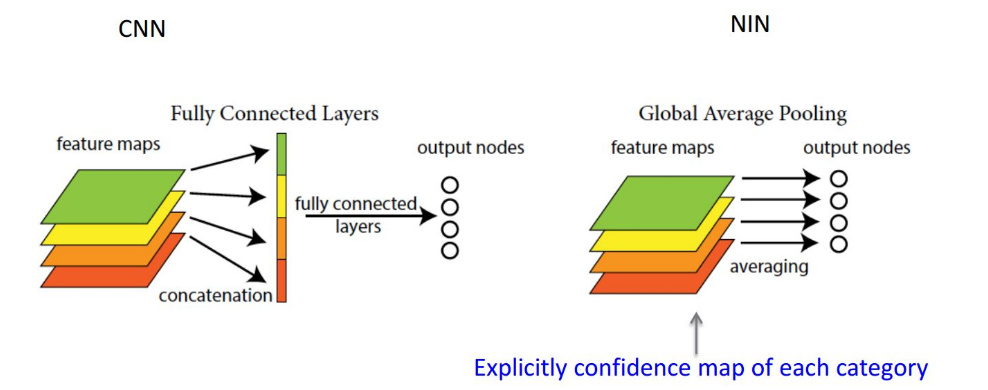
Global Average Pooling
传统的 cnn 是在较低层使用卷积,如分类任务中,最后的卷积层所得 feature map 被矢量化进行全连接层,然后使用 softmax 回归进行分类。一般来说,在卷积的末端完成的卷积与传统分类器的桥接。全连接阶段易于过拟合,妨碍整个网络的泛化能力,一般应有一些规则方法来处理过拟合。
在传统 CNN 中很难解释最后的全连接层输出的类别信息的误差怎么传递给前边的卷积层。而 global average pooling 更容易解释。另外,全连接层容易过拟合,往往依赖于 dropout 等正则化手段.
global average pooling 的概念非常简单,分类任务有多少个类别,就控制最终产生多少个 feature map. 对每个 feature map 的数值求平均作为某类别的置信度,类似 FC 层输出的特征向量,再经过 softmax 分类。其优点有:
- 参数数量减少,减轻过拟合 (应用于 AlexNet, 模型 230MB->29MB);
- 更符合卷积网络的结构,使 feature map 和类别信息直接映射;
- 求和取平均操作综合了空间信息,使得对输入的空间变换更鲁棒 (与卷积层相连的 FC 按顺序对特征进行了重新编排 (flatten), 可能破坏了特征的位置信息).
- FC 层输入的大小须固定,这限制了网络输入的图像大小