Attention
上面这个视频很好的总结了 Attention 的各个步骤:
- 首先收集 (储存) Encoder 的每一步的隐藏状态的输出向量。
- 对每个隐藏状态进行评分(先不考虑如何评分)。
- 对评分进行 Softmax 概率化。
- 把得到的概率与对应的输出向量相乘,放大具有高分数的隐藏状态,淹没低分数的隐藏状态。
- 对加权后的向量求和,得到输出。
在具体的每一个时间单元步里面执行过程如下:
- Decoder RNN 接受’
‘的词向量和 Decoder 的初始向量。 - 经过 RNN 处理,产生输出和隐藏向量 (h4), 丢掉输出。
- Attention: 使用储存的 Encoder 词向量和 h4 向量来计算时间步的上下文向量 (C4)。
- h4 和 C4 进行拼接得到这一个 RNN 的输出。
- 通过 Dense+softmax 来得到字典中每个字的概率,从而最大化输出字标签。
- 这一时间步执行完毕,把 h4 传递到下一个 RNN, 下一个 RNN 的输入为上一个 RNN 的输出。
把每一个时间步骤汇总起来就得到了最后的输入输出的 Attention 矩阵: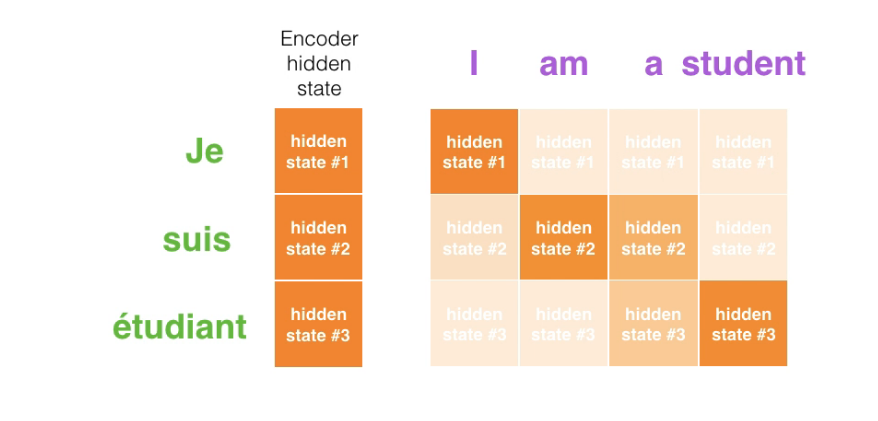
上面的过程搞明白后,现在的问题就是怎么对几个向量进行评分。
Transformer (Attention Is All You Need)
正如论文的题目所说的,Transformer 中抛弃了传统的 CNN 和 RNN,整个网络结构完全是由 Attention 机制组成。更准确地讲,Transformer 由且仅由 self-Attenion 和 Feed Forward Neural Network 组成。一个基于 Transformer 的可训练的神经网络可以通过堆叠 Transformer 的形式进行搭建,作者的实验是通过搭建编码器和解码器各 6 层,总共 12 层的 Encoder-Decoder,并在机器翻译中取得了 BLEU 值得新高。
作者采用 Attention 机制的原因是考虑到 RNN(或者 LSTM,GRU 等)的计算限制为是顺序的,也就是说 RNN 相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 t 的计算依赖 t-1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管 LSTM 等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM 依旧无能为力。

