比赛介绍
Quora 平台,简单的来说就是美国版的知乎。最近 Quora 拿出 25,000 美元作为奖金,举办了一场 Kaggle 比赛:Quora Insincere Questions Classification。那么什么是虚假问题呢?就是那些并非真心发问而另有用意的问题。
该竞赛是个典型的文本二分类问题,即判断用户的提问是否 “有害”,竞赛中最关键的要求有三点:
- 只能使用 Kaggle Kernel 中生成的 submission.csv 来提交;
- 不能使用外部数据,也就是说 embedding 也只能用 Kernel 里提供的四个 embedding 文件;
- Kernel 的 GPU 运行时间不能超过 120 分钟。也就是说不能使用 Bert 这样的大型模型。
目前的排名也不是最终排名,最后官方会用另一部分数据集来测试模型,然后给出最终的排名。
官方的四个 embedding 文件
从公开的 Kernel 来看,目测有 99% 都是使用 RNN 来解题。这 99% 使用 RNN 模型的,目测有 80% 都是使用了 Keras。文本分类
最常见的文本分类应用场景就是垃圾邮件分类,情感分类等等。
检查数据
首先加载数据集,然后对数据集进行检查。可以随机打印一些样本然后查看是不是和标签相对应 (df.sample)探索数据集并收集指标
收集以下有助于表征文本分类问题的重要指标: - 样本数:数据中的示例总数。
- 课程数量:数据中的主题或类别总数。
- 每个类的样本数:每个类的样本数(主题 / 类别)。在平衡数据集中,所有类都将具有相似数量的样本;在不平衡的数据集中,每个类中的样本数量会有很大差异。
- 每个样本的单词数:一个样本中的单词中位数。
- 单词的频率分布:显示数据集中每个单词的频率(出现次数)的分布。
- 样本长度分布:分布显示数据集中每个样本的单词数。
explore_data.py contains functions to calculate and analyse these metrics.
选择模型
这里谷歌给出了一个文本分类模型选择的流程图。
我们针对不同类型的问题(特别是情绪分析和主题分类问题)运行了大量(~450K)实验,使用 12 个数据集,交替用于不同数据预处理技术和不同模型体系结构之间的每个数据集。这有助于我们识别影响最佳选择的数据集参数。下面的模型选择算法和流程图是我们实验的总结。
Algorithm for Data Preparation and Model Building
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
2. If this ratio is less than 1500, tokenize the text as n-grams and use a
simple multi-layer perceptron (MLP) model to classify them (left branch in the
flowchart below):
a. Split the samples into word n-grams; convert the n-grams into vectors.
b. Score the importance of the vectors and then select the top 20K using the scores.
c. Build an MLP model.
3. If the ratio is greater than 1500, tokenize the text as sequences and use a
sepCNN model to classify them (right branch in the flowchart below):
a. Split the samples into words; select the top 20K words based on their frequency.
b. Convert the samples into word sequence vectors.
c. If the original number of samples/number of words per sample ratio is less
than 15K, using a fine-tuned pre-trained embedding with the sepCNN
model will likely provide the best results.
4. Measure the model performance with different hyperparameter values to find
the best model configuration for the dataset.
````
翻译一下:
1. 计算每个样本比例的样本数/单词数的比率。
2. 如果此比率小于1500,则将文本标记为n-gram并使用简单的多层感知器(MLP)模型对它们进行分类(左侧分支)下面的流程图):一个。将样本分成单词n-gram; 将n-gram转换为向量。湾 评分向量的重要性,然后使用分数选择前20K。C。建立MLP模型。
3. 如果比率大于1500,则将文本标记为序列并使用sepCNN模型对它们进行分类(右下图在下面的流程图中):一个。将样本分成单词; 根据频率选择前20K字。湾 将样本转换为单词序列向量。C。如果原始样本数/每个样本的单词数比例较小超过15K,使用经过微调的预训练嵌入sepCNN模型可能会提供最好的结果。
4. 使用不同的超参数值测量模型性能以进行查找数据集的最佳模型配置。
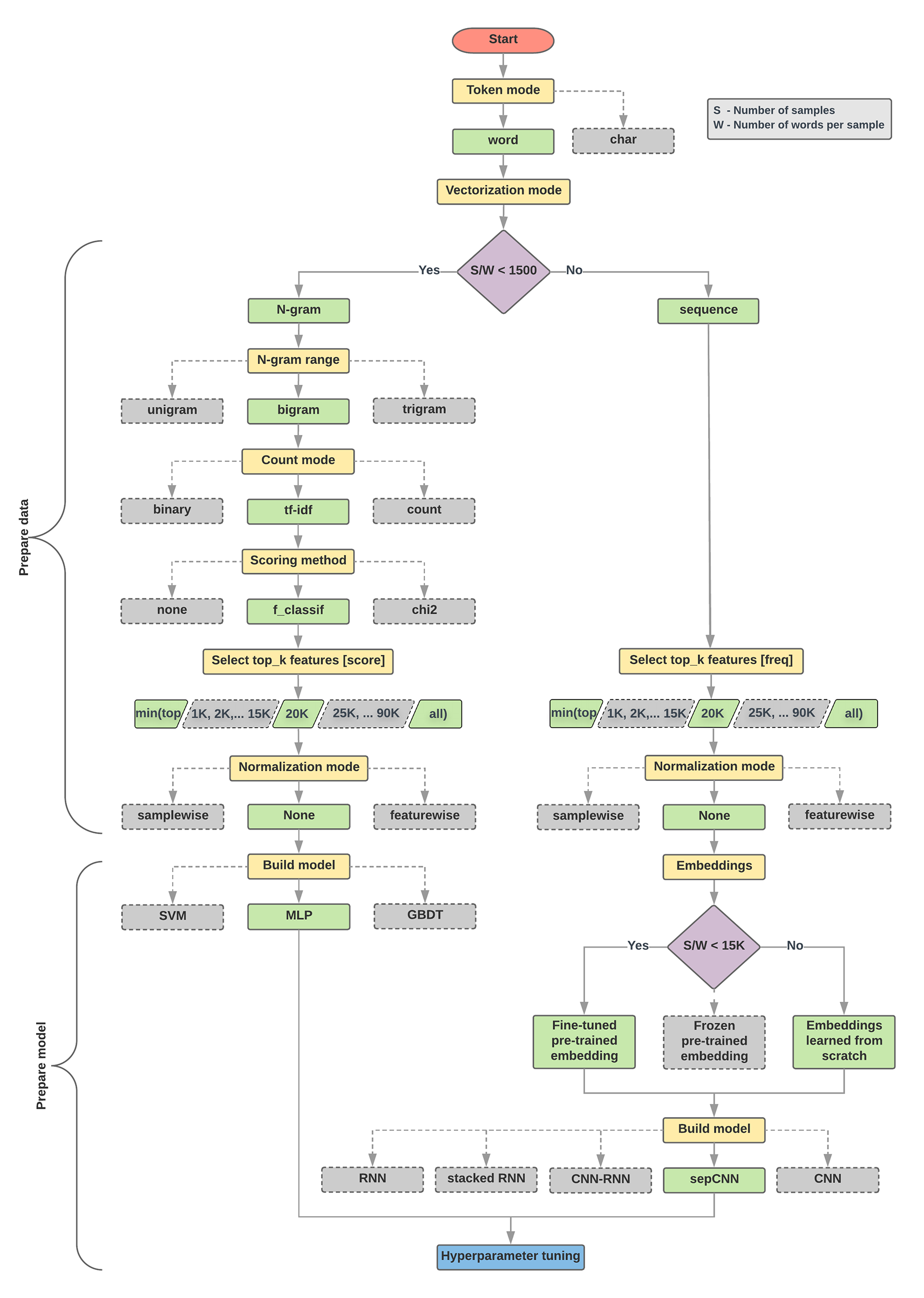文本分类模型选择流程图
>在下面的流程图中,黄色框表示数据和模型准备过程。灰色框和绿色框表示我们为每个过程考虑的选择。绿色框表示我们对每个过程的建议选择。您可以使用此流程图作为构建第一个实验的起点,因为它可以以较低的计算成本为您提供良好的准确性。然后,您可以在后续迭代中继续改进初始模型。
此流程图回答了两个关键问题:
- 我们应该使用哪种学习算法或模型?
- 我们应该如何准备数据以有效地学习文本和标签之间的关系?
第二个问题的答案取决于第一个问题的答案; 我们预先处理数据的方式将取决于我们选择的模型。模型可以大致分为两类:使用单词排序信息的那些(序列模型),以及仅将文本视为“包”(组)单词(n-gram模型)的模型。序列模型的类型包括卷积神经网络(CNN),递归神经网络(RNN)及其变体。n-gram模型的类型包括逻辑回归,简单的多层感知器(MLP或完全连接的神经网络),梯度增强树和支持向量机。
根据我们的实验,我们观察到“样本数”(S)与“每个样本的单词数”(W)的比率与哪个模型表现良好相关。
当该比率的值很小(<1500)时,以n-gram为输入的小型多层感知器(我们称之为选项A)表现得更好或至少与序列模型一样好。MLP很容易定义和理解,并且它们比序列模型花费更少的计算时间。当此比率的值很大(> = 1500)时,使用序列模型(选项B)。在接下来的步骤中,您可以根据样本/单词样本比率跳过所选模型类型的相关小节(标记为A或B)。
### 数据集的平衡性
对于分类的数据集来说,每个类中的样本数量不会过度失衡,也就是说,每个类中应该有相当数量的样本。但是这个比赛就是一个严重不平衡的数据集。
### 常用深度学习模型

## 常用代码总结
这里是英文数据集数据处理和Keras搭建模型的一些常用代码。Using pre-trained word embeddings in a Keras model](https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html)。
### Token and Padding
```python
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(nb_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# split the data into a training set and a validation set
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
nb_validation_samples = int(VALIDATION_SPLIT * data.shape[0])
x_train = data[:-nb_validation_samples]
y_train = labels[:-nb_validation_samples]
x_val = data[-nb_validation_samples:]
y_val = labels[-nb_validation_samples:]Preparing the Embedding layer
- Reading the data dump of pre-trained embeddings
2
3
4
5
6
7
8
9
10
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))- Compute our embedding matrix:
2
3
4
5
6
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector- Build embedding layer
2
3
4
5
6
7
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)Keras F1 Socre
使用的时候:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def recall(y_true, y_pred):
"""Recall metric.
Only computes a batch-wise average of recall.
Computes the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def precision(y_true, y_pred):
"""Precision metric.
Only computes a batch-wise average of precision.
Computes the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
precision = precision(y_true, y_pred)
recall = recall(y_true, y_pred)
return 2*((precision*recall)/(precision+recall+K.epsilon()))
2
3
4
loss='binary_crossentropy',
optimizer=adam,metrics=[F1])
print(model.summary())Keras Attention Layer
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
def __init__(self, step_dim,
W_regularizer=None, b_regularizer=None,
W_constraint=None, b_constraint=None,
bias=True, **kwargs):
self.supports_masking = True
# self.init = initializations.get('glorot_uniform')
self.init = initializers.get('glorot_uniform')
self.W_regularizer = regularizers.get(W_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.b_constraint = constraints.get(b_constraint)
self.bias = bias
self.step_dim = step_dim
self.features_dim = 0
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 3
self.W = self.add_weight((input_shape[-1],),
initializer=self.init,
name='{}_W'.format(self.name),
regularizer=self.W_regularizer,
constraint=self.W_constraint)
self.features_dim = input_shape[-1]
if self.bias:
self.b = self.add_weight((input_shape[1],),
initializer='zero',
name='{}_b'.format(self.name),
regularizer=self.b_regularizer,
constraint=self.b_constraint)
else:
self.b = None
self.built = True
def compute_mask(self, input, input_mask=None):
# do not pass the mask to the next layers
return None
def call(self, x, mask=None):
input_shape = K.int_shape(x)
features_dim = self.features_dim
# step_dim = self.step_dim
step_dim = input_shape[1]
eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)), K.reshape(self.W, (features_dim, 1))), (-1, step_dim))
if self.bias:
eij += self.b[:input_shape[1]]
eij = K.tanh(eij)
a = K.exp(eij)
# apply mask after the exp. will be re-normalized next
if mask is not None:
# Cast the mask to floatX to avoid float64 upcasting in theano
a *= K.cast(mask, K.floatx())
# in some cases especially in the early stages of training the sum may be almost zero
# and this results in NaN's. A workaround is to add a very small positive number ε to the sum.
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
a = K.expand_dims(a)
weighted_input = x * a
# print weigthted_input.shape
return K.sum(weighted_input, axis=1)
def compute_output_shape(self, input_shape):
# return input_shape[0], input_shape[-1]
return input_shape[0], self.features_dim
# end Attention加载 IMDB 电影评论数据集
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
"""Loads the IMDb movie reviews sentiment analysis dataset.
# Arguments
data_path: string, path to the data directory.
seed: int, seed for randomizer.
# Returns
A tuple of training and validation data.
Number of training samples: 25000
Number of test samples: 25000
Number of categories: 2 (0 - negative, 1 - positive)
# References
Mass et al., http://www.aclweb.org/anthology/P11-1015
Download and uncompress archive from:
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
"""
imdb_data_path = os.path.join(data_path, 'aclImdb')
# Load the training data
train_texts = []
train_labels = []
for category in ['pos', 'neg']:
train_path = os.path.join(imdb_data_path, 'train', category)
for fname in sorted(os.listdir(train_path)):
if fname.endswith('.txt'):
with open(os.path.join(train_path, fname)) as f:
train_texts.append(f.read())
train_labels.append(0 if category == 'neg' else 1)
# Load the validation data.
test_texts = []
test_labels = []
for category in ['pos', 'neg']:
test_path = os.path.join(imdb_data_path, 'test', category)
for fname in sorted(os.listdir(test_path)):
if fname.endswith('.txt'):
with open(os.path.join(test_path, fname)) as f:
test_texts.append(f.read())
test_labels.append(0 if category == 'neg' else 1)
# Shuffle the training data and labels.
random.seed(seed)
random.shuffle(train_texts)
random.seed(seed)
random.shuffle(train_labels)
return ((train_texts, np.array(train_labels)),
(test_texts, np.array(test_labels)))Keras EarlyStopping
2
3
4
5
6
7
8
early_stopping = EarlyStopping(monitor='val_loss', patience=3)
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=train_epochs,
validation_data=(x_val, y_val),verbose = 2,
callbacks=[early_stopping])
- monitor: 需要监视的量,val_loss,val_acc
- patience: 当 early stop 被激活 (如发现 loss 相比上一个 epoch 训练没有下降),则经过 - —patience 个 epoch 后停止训练
- verbose: 信息展示模式,默认为 1,显示详细信息,2 是一轮显示最终信息,0 是不显示。
- mode: ‘auto’,’min’,’max’之一,在 min 模式训练,如果检测值停止下降则终止训练。在 max 模式下,当检测值不再上升的时候则停止训练。
Keras Adam 默认参数
Adam 优化器由 Kingma 和 Lei Ba 在 Adam: A method for stochasticoptimization。默认参数是文章中建议的。
1 | keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-8, kappa=1-1e-8) |
可以在模型early_stopping后换用低一点的学习率继续训练两个epoch。
一些经验
- 在