Memory Networks
论文简介
- Memory Networks ,ICLR 2015,Facebook AI Research
- Answering Reading Comprehension Using Memory Networks,Stanford
(2018 年 12 月 3 日补充:第二篇不是论文,应该是斯坦福写的一个类似教程之类的东西,但是写的太像论文了 (ˇˍˇ),我都搞混了 )
看名字就知道第一篇是原论文,第二篇是第一篇的实现。(这里必须吐槽一下,第一篇论文一个图都没有,让我这种看论文先看图的人瞬间丧失好感。第二篇就人性化的多,简单的一个模型架构图就能瞬间让人领悟许多。)
- 起因:作者认为 RNN、Attention 机制把很长的语句编码为定长向量 (Context Vector) 作为模型的记忆,会带来很大的信息压缩损失
- 想法: 既然是因为向量太小带来的问题,那就直接加一个外部记忆模块,称之为 Memory
- 评价:开山之作,但是模型比较简单,也没有特别具体的说明。
在第二篇论文里面的引言部分有一些比较精辟的话,我也摘录出来,不妨作为 NLP 的部分真理以供参考。
- QA 是最容易评估 AI 的标准。(这个容易理解,图灵测试不就是这样吗?)
- AI 要想很好的完成 QA 任务,要在两个方面得到提高:检索和推理。
- 单纯的记忆是不够的,他们需要一些知识去检索。(人不也经常使用浏览器吗?)
具体实现
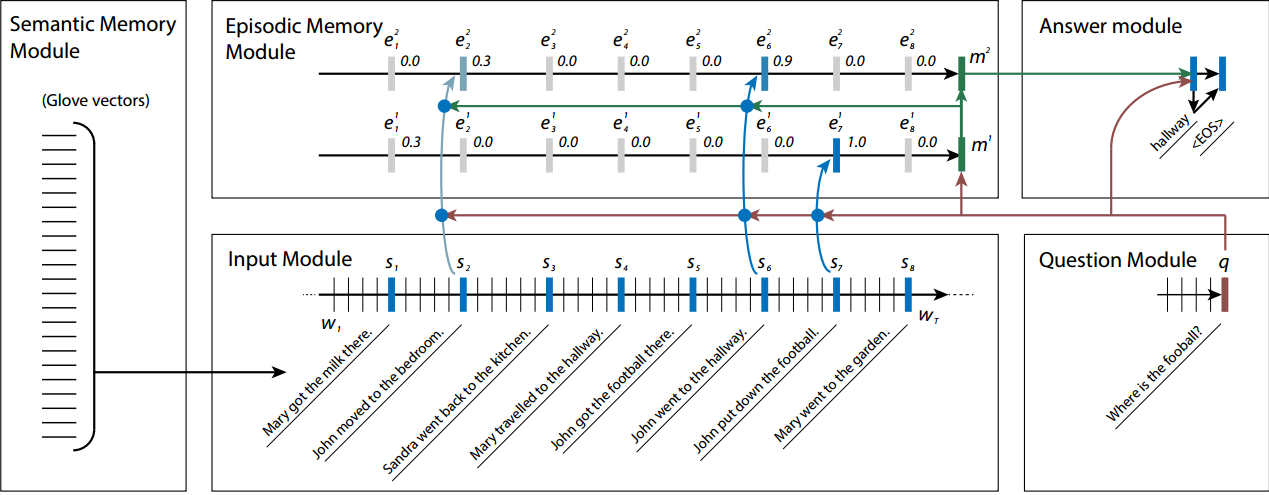
看下面这个图就很清楚,这个模型主要包括五个部分:Memory 单元和 I、G、O、R。
- Input 模块:输入的文本经过 Input 模块编码成特征向量 (各种方式都可以,最简单就是 wordvec)。
- Generalization 模块:根据特征向量对 Memory 单元进行读写操作,即更新记忆。
- Output 模块:根据 Question(也会进过 Input 模块进行编码)对 Memory 单元进行组合(比如加权),得到编码的输出向量
- Response 模块:根据输出向量编码生成一个自然语言的答案出来。
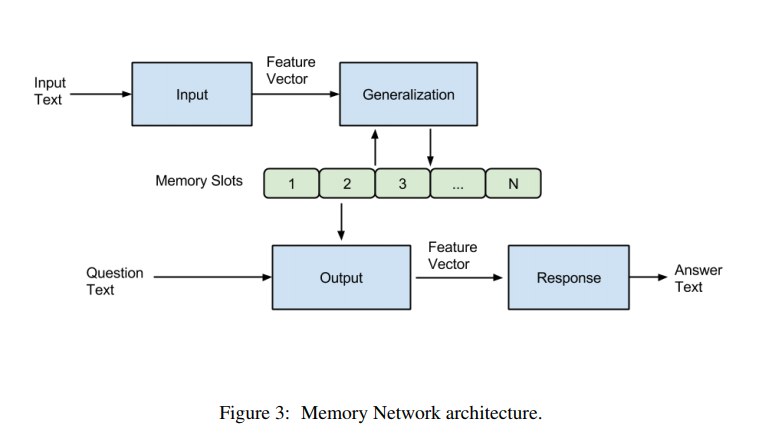
举个例子。假设有下面一段文字,针对文字可以提出几个问题,然后让模型去回答:

这里我们首先使用 Input 模块对文档进行编码,Generalization 模块存储编码结果,然后使用 Input 对问题 where is the milk now?进行编码,Output 模块根据问题编码后的向量从 Memory 单元中选出最相关的一句话:Joe left the milk,然后再对剩下的记忆进行评分,找出与 where is the milk now?和 Joe left the milk 最相关的 memory。我们发现是 Joe travelled to the office。这样我们就找到了最相关的记忆,接下来使用 R 模块对所有的单词进行评分找到得分最高的单词作为答案即可。
代码复现
End-To-End Memory Networks
论文简介
- End-To-End Memory Networks,Facebook AI Research
这是 Facebook AI 在 Memory networks 后的续作。上文记忆网络介绍模型并非端到端的 QA 训练,该论文 End-To-End Memory Networks 就在上文的基础上进行端到端的模型构建,减少生成答案时需要事实依据的监督项,在实际应用中应用意义更大。
End to end:一端输入我的原始数据,一端输出我想得到的结果。只关心输入和输出,中间的步骤全部都不管。
具体实现
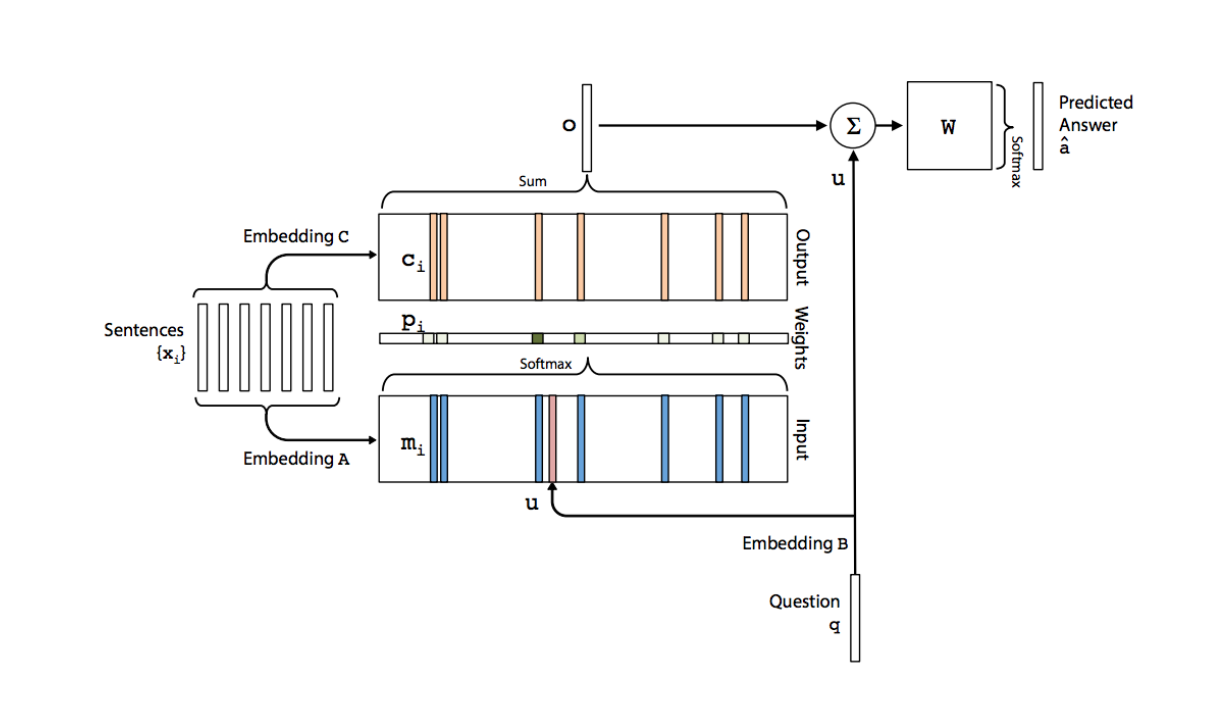
这一篇文章提到一个更加具体但是复杂一点的模型如上图所示。
模型主要的参数包括 A,B,C,W 四个矩阵,其中 A,B,C 三个矩阵就是 embedding 矩阵,主要是将输入文本和 Question 编码成词向量,W 是最终的输出矩阵。从上图可以看出,对于输入的句子 s 分别会使用 A 和 C 进行编码得到 Input 和 Output 的记忆模块,Input 用来跟 Question 编码得到的向量相乘得到每句话跟 q 的相关性,Output 则与该相关性进行加权求和得到输出向量。然后再加上 q 并传入最终的输出层。
输入输出模块
通过把每句话压缩成一个向量对应到 memory 中的一个 slot(上图中的蓝色或者黄色竖条),将输入的文本转化成向量并保存在 memory 中 (通过词向量得到句向量)。论文中提出了两种编码方式,BoW 和位置编码:
- BoW:直接把词向量加起来,会丢失位置关系。
- 位置编码:认为不同位置的单词的权重是不一样的,然后对各个单词的词向量按照不同位置权重进行加权求和得到句子表示。
输入模块把输入文本编码为向量,保存在 Input 和 Output 两个模块中,Input 模块用于跟 Question 相互作用得到各个 memory slot 与问题的相关程度,使用 Output 模块的信息产生输出。
- Input 模块:将 Question 经过输入模块编码成一个向量 u,与 $m{i}$ 维度相同,然后将其与每个 $m{i}$ 点积得到两个向量的相似度,在通过一个 softmax 函数进行归一化得到 $p{i}$,$p{i}$ 就是 q 与 $m_{i}$ 的相关性指标。
- Output 模块:对其中各个记忆 ci 按照 pi 进行加权求和即可得到模型的输出向量 o。
Response 模块
Response 模块主要是根据输出向量 o 和问题向量 q 产生最终的答案。其结合 o 和 q 两个向量的和与 W 相乘在经过一个 softmax 函数产生各个单词是答案的概率,值最高的单词就是答案。并且使用交叉熵损失函数最为目标函数进行训练。
多层模型
将多个单层模型进行 stack 在一块,结构图如下所示:
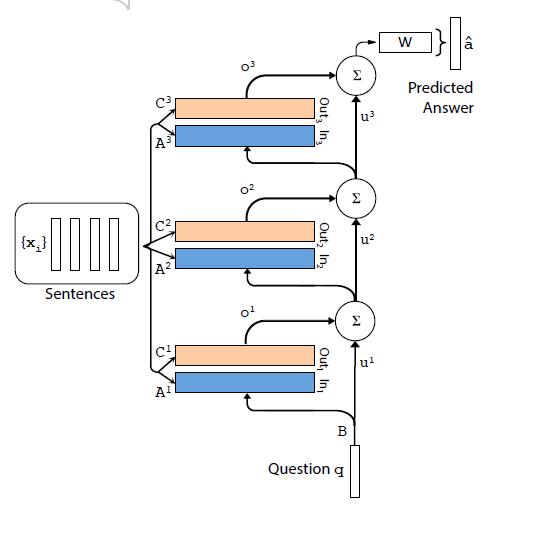
上面几层的输入就是下层 o 和 u 的和。至于各层的参数选择,论文中提出了两种方法(主要是为了减少参数量,如果每层参数都不同的话会导致参数很多难以训练)。
- Adjacent:这种方法让相邻层之间的 A=C。也就是说 $A {k}+1=C_{k}$,此外 W 等于顶层的 C,B 等于底层的 A,这样就减少了一半的参数量。
- Layer-wise(RNN-like):与 RNN 相似,采用完全共享参数的方法,即各层之间参数均相等。由于这样会大大的减少参数量导致模型效果变差,所以提出一种改进方法,即令 $u{k+1}=u{k}+o_{k}$,也就是在每一层之间加一个线性映射矩阵 H。
论文公式
具体的公式如下:

代码实现
Dynamic Memory Networks
论文简介
论文中说 NLP 中很多任务都可以归结为 QA 问题,所以本文的 DMN 模型以 QA 为基础进行训练,但是可以扩展到很多别的任务中,包括序列标注、分类、翻译等等。
具体实现