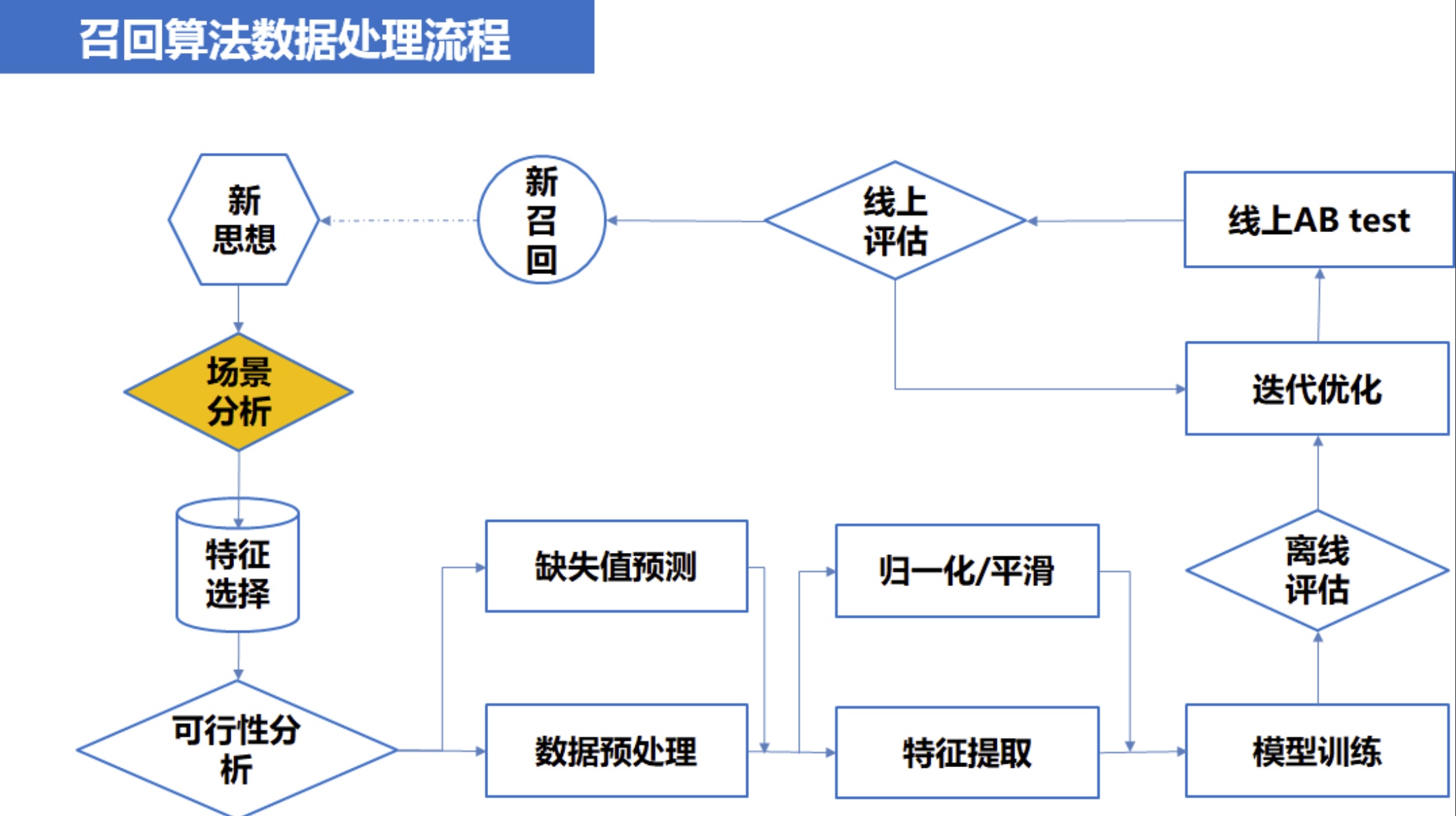
推荐系统整体流程
- 多路召回:首先召回阶段是会配置召回的请求个数,通常会根据每路召回的后验表现设置动态配比,或者是根据业务的需求进行设置。所有的召回并发请求并设置 timeout,防止系统雪崩。
- 所有的召回结果 merge。
- 过滤:系统整体的黑名单,以及 by user 的黑名单过滤都可以在此处实现。
- 去重:此处通常都是简单的指纹去重,不做特别精细的多样性去重(比如相似新闻通常在排序后做)。(过滤和去重都是为了减少后续系统的压力,防止浪费算力进行后续步骤。)
- 粗排后截断。当然粗排也可以放在每个召回队列中做,也是根据业务而定。
- 进行精排。
- 排序后的 rerank 处理,包括多样性去重,产品的特殊 boost 逻辑等。
什么是召回
召回系统,本质上是个信息漏斗,负责快速从海量信息中筛选出有价值的信息,缩小排序算法的搜素范围;也负责将多路召回的数据,进行信息融合,最后得到一个精简的候选集。
召回的特性
处理的数据量非常大,速度要求快,所有使用的模型和特征都不能太复杂。
召回的重要性
- 奠基性:后续流程,基于召回数据展开
- 桥接性:建立用户和内容的桥梁
- 决定性:召回质量决定推荐质量
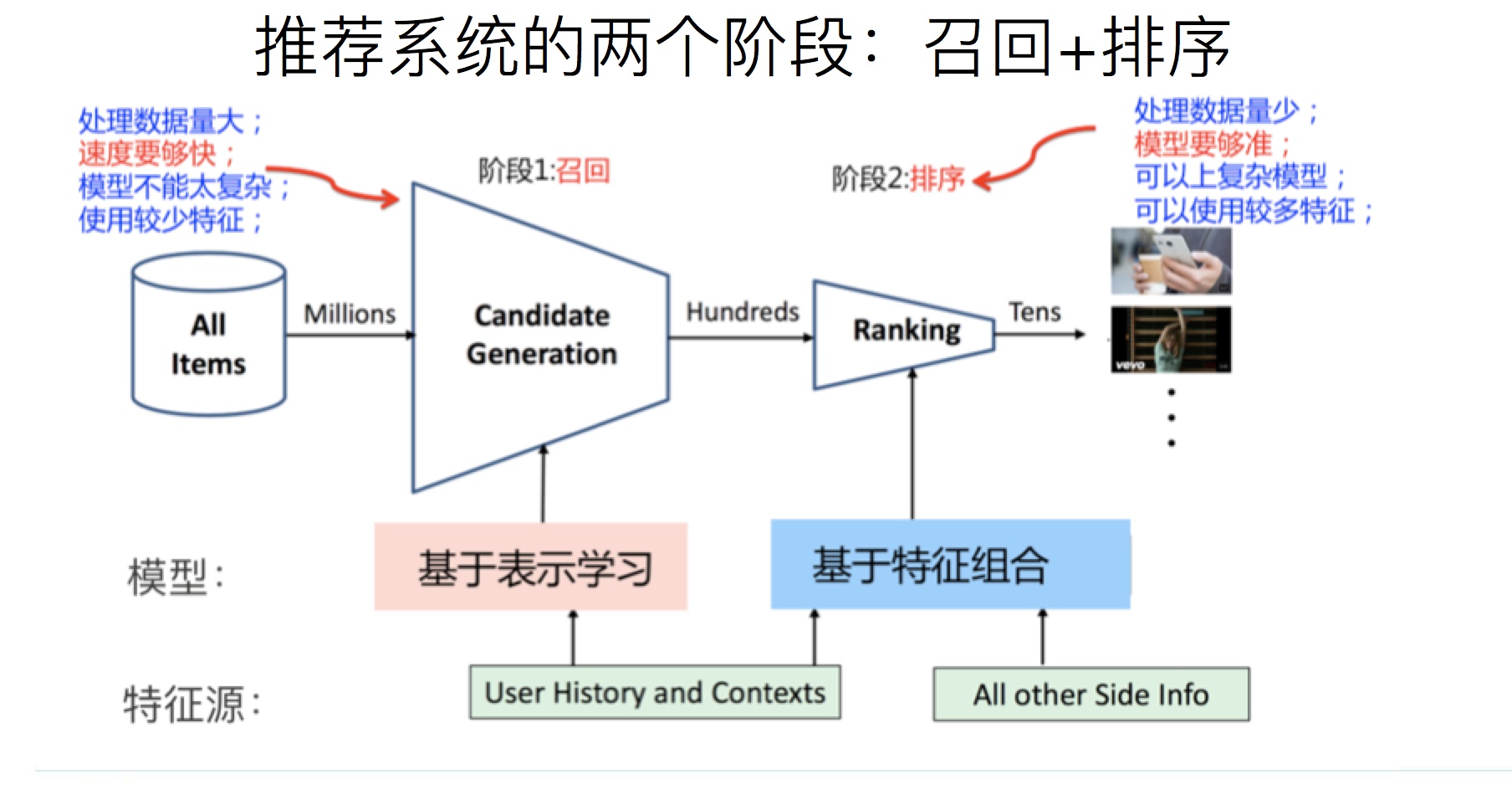
多路召回
如下图所示,每种算法按照各自的召回配比份额,进行召回对应数目的 item, 再进行去重 merge; 或者排序无性能压力的情况下,分别召回各自子召回域,再去重 merge; 亦或投票等等规则,得到我们推荐系统想要的召回池。
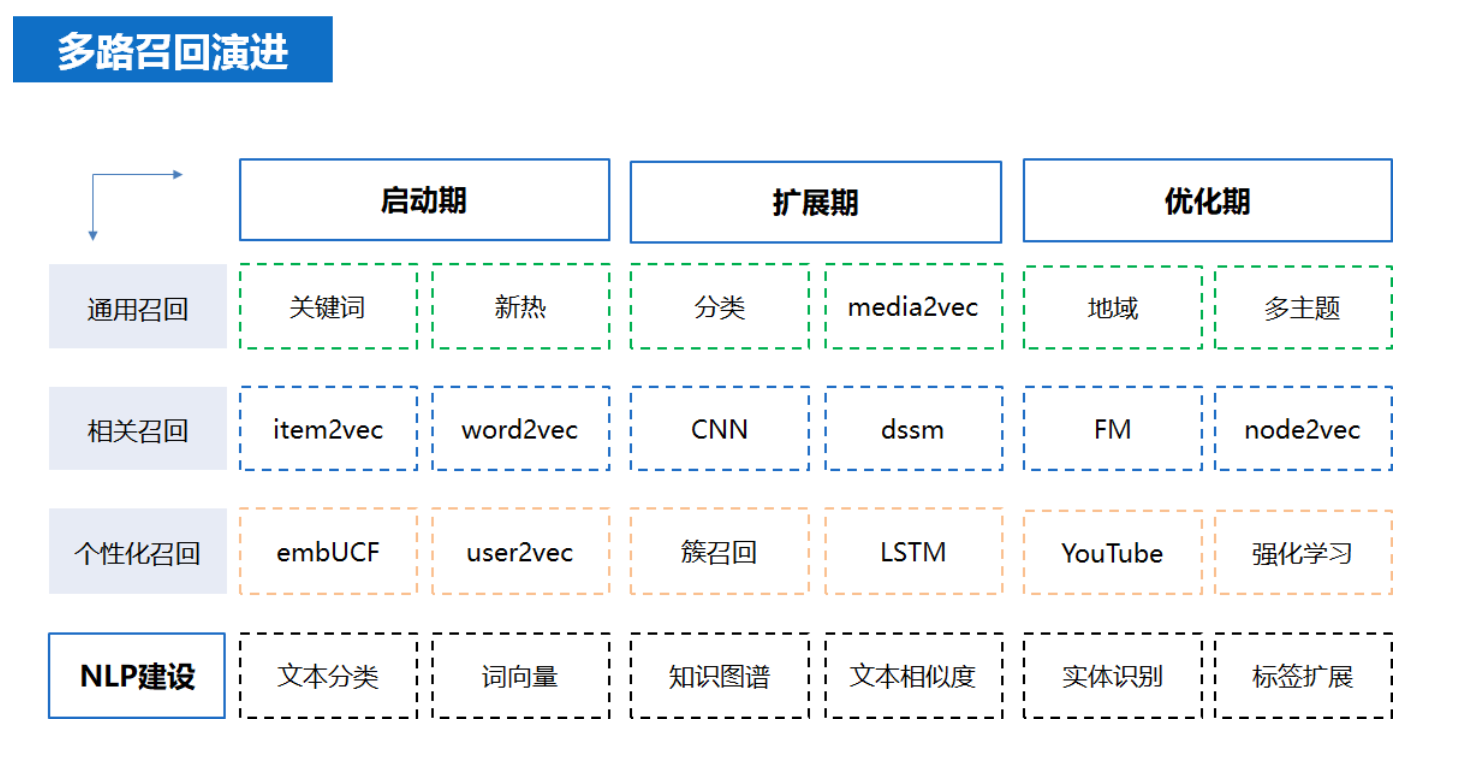
多路召回的演进
- 基于内容的召回:使用 item 之间的相似性来推荐与用户喜欢的 item 相似的 item
- 协同过滤:同时使用 query 和 item 之间的相似性来进行推荐。
- 基于 FM 模型召回:FM 是基于矩阵分解的推荐算法,其核心是二阶特征组合。
- 基于深度神经网络的方法:利用深度神经网络生成相应的候选集。
评价指标
真假正负
举一个狼来了的例子:
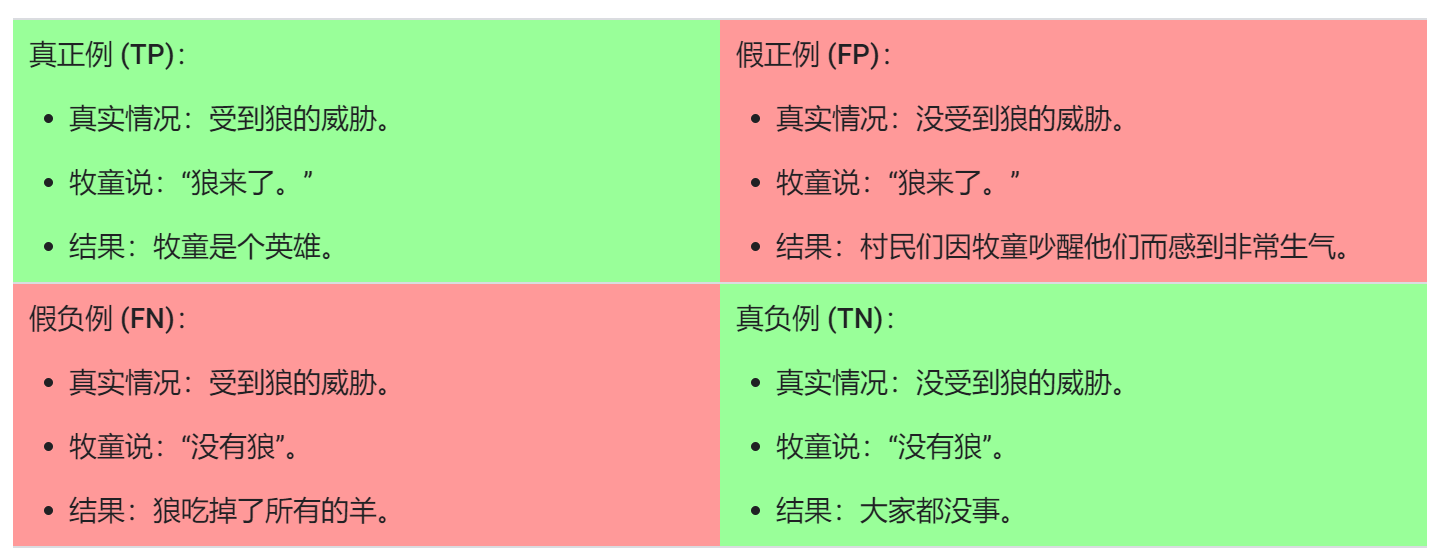
- 真正例是指模型将正类别样本正确地预测为正类别。
- 真负例是指模型将负类别样本正确地预测为负类别。
- 假正例是指模型将负类别样本错误地预测为正类别
- 假负例是指模型将正类别样本错误地预测为负类别。
准确率
准确率是指我们的模型预测正确的结果所占的比例,定义如下
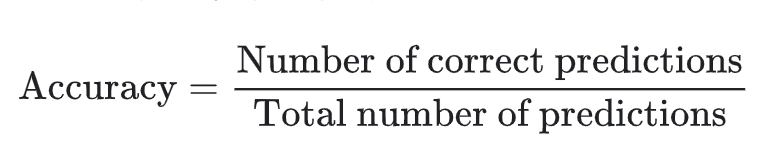
对于二分类,也可以根据正类别和负类别按如下方式计算准确率:
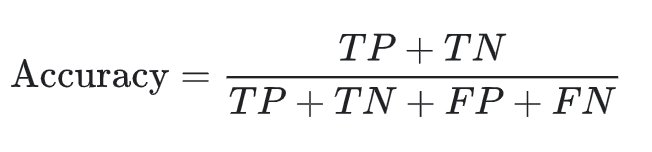
其中,TP = 真正例,TN = 真负例,FP = 假正例,FN = 假负例。
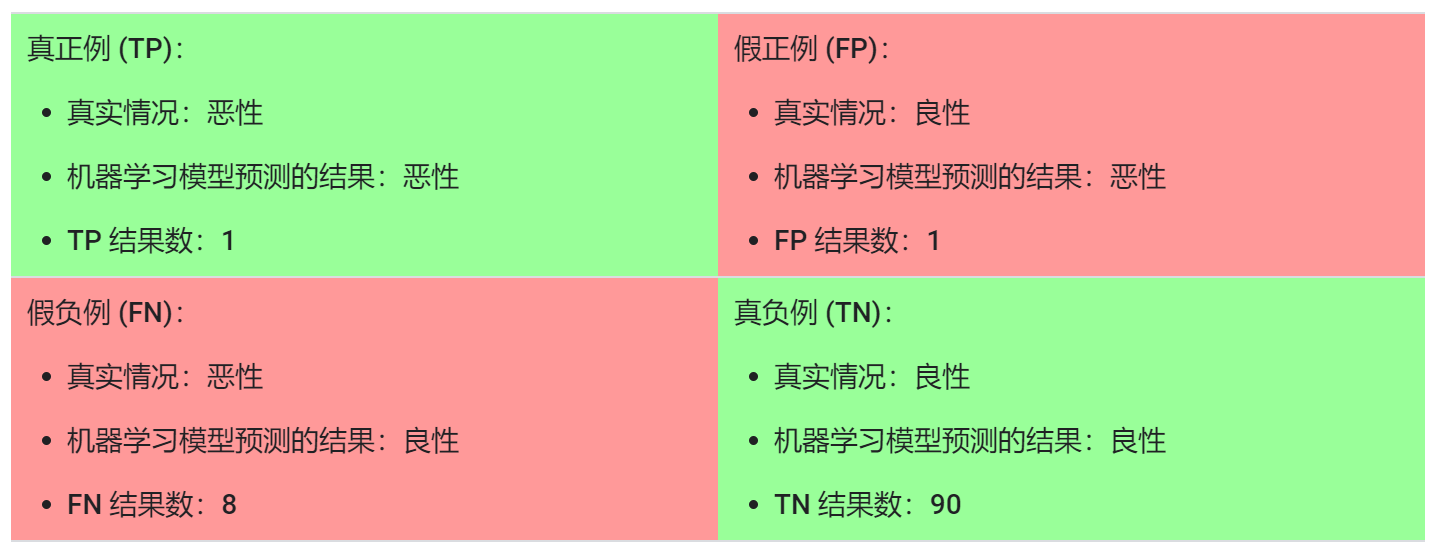
但是这个评估指标对于样本不均衡问题并不起作用。假设有下面的模型可以将 100 个肿瘤分为恶性(正类别)或良性(负类别):
按照正确率的计算公式:
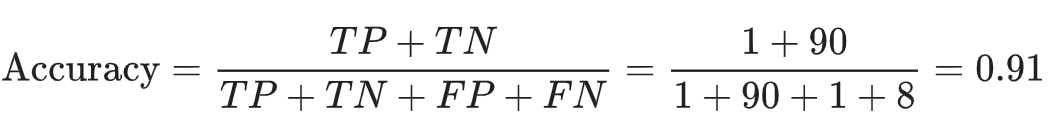
看起来这个肿瘤分类器在识别恶性肿瘤方面表现得非常出色,对吧?但是实际上,只要我们仔细分析一下正类别和负类别,就可以更好地了解我们模型的效果。
在 100 个肿瘤样本中,91 个为良性(90 个 TN 和 1 个 FP),9 个为恶性(1 个 TP 和 8 个 FN)。在 91 个良性肿瘤中,该模型将 90 个正确识别为良性。这很好。不过,在 9 个恶性肿瘤中,该模型仅将 1 个正确识别为恶性。这是多么可怕的结果!9 个恶性肿瘤中有 8 个未被诊断出来!这说明我们的模型并没有区分恶性肿瘤和良性肿瘤的能力。
对于分类不平衡的数据集(比如正类别标签和负类别标签的数量之间存在明显差异)时,单单准确率一项并不能反映全面情况。在下一部分中,我们将介绍两个能够更好地评估分类不平衡问题的指标:精确率和召回率。
精确率和召回率


要全面评估模型的有效性,必须同时检查精确率和召回率。精确率和召回率往往是此消彼长的情况,也就是说,提高精确率通常会降低召回率值,反之亦然。
召回的评测方法
在现有的个性化召回体系下,如果要新增一种个性化召回算法,需要知道这种个性化召回算法会对系统造成怎样的影响,是正向收益还是负向收益。所以经过离线和在线两个步骤的评测:
- 离线评测:是作为能否进入线上的标准,主要是通过历史数据,场景重现,看用户反馈的各项指标是否有所提升,指标包括模型指标(P 值,r 值,F1 值等),业务指标 (CTR,CVR)。
- 在线评测:主要是通过逐级增大流量的 AB 实验的方法,进行测试,观察各种业务的在线指标,比如 CTR,CVR,GMV 等。