
更改评价指标
准确率肯定是不行的,一般会选择 F1 值或者 AUC_ROC 来作为评价指标
数据层面
数据的采样,过采样或者欠采样
- 过采样是从少数类样本集 Smin 中随机重复抽取样本( 有放回)
- 欠采样是从多数类样本集 Smaj 中随机选取较少的样本( 有放回或无放回)
直接的随机采样虽然可以使样本集变得均衡,但会带来一些问题,比如,过采样对少数类样本进行了多次复制,扩大了数据规模,增加了模型训练的复杂度,同时也容易造成过拟合; 欠采样会丢弃一些样本,可能会损失部分有用信息, 造成模型只学到了整体模式的一部分。
模型方法
更改损失函数,例如类别加权损失或者 Focal Loss
Focal loss 主要是为了解决 one-stage 目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重。
回顾二分类交叉上损失: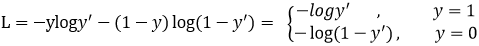
普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。
现在记:
这样 $p_t$ 实际上就是反映了 p 与 y 的接近程度。$p_t$ 越大,说明分类越好。交叉熵损失函数的最终形式为:
通过实验发现,即使是 easy examples,由于它们数量很多,它的 loss 也很高,如下图蓝线。这些 loss 会主导梯度下降的方向,淹没少量的正样本的影响。$p_t$ 越大,FL 越小,总体 Loss 越小。增加了误分类的重要性。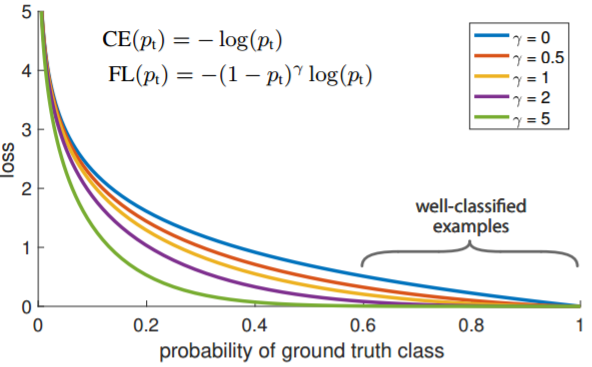
参数为 0 的时候,Focal Loss 退化为交叉熵 CE。从图中我们可以很直观地看到,
集成方法
每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果。
这种解决问题的思路类似于随机森林。在随机森林中,虽然每个小决策树的分类能力很弱,但是通过大量的 “小树” 组合形成的 “森林” 具有良好的模型预测能力。

