概率图模型
概率图模型(probabilistic graphical model, PGM)指用图表示变量相关(依赖)关系的概率模型,主要分为两类:
- 有向图模型或贝叶斯网(Bayesian network),使用有向图表示变量间的依赖关系;
- 无向图模型或马尔可夫网(Markov network),使用无向图表示变量间相关关系。
PGM 对应的图有两种表示形式:independency graph, factor graph. independency graph 直接描述了变量的条件独立,而 factor graph 则是通过因子分解( factorization)的方式暗含变量的条件独立。比如,NB 与 HMM 所对应的两种图表示如下: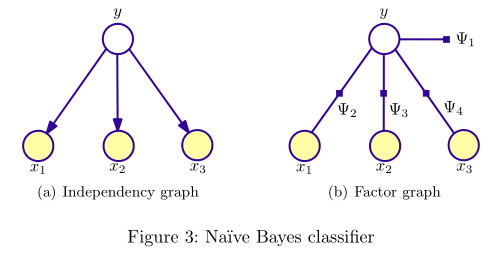
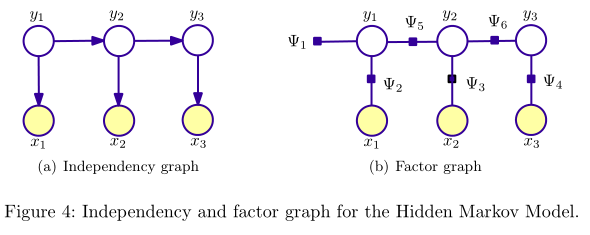
可以看出,NB 与 HMM 所对应的 independency graph 为有向图。
从生成随机模型和判别式模型的角度可以得到: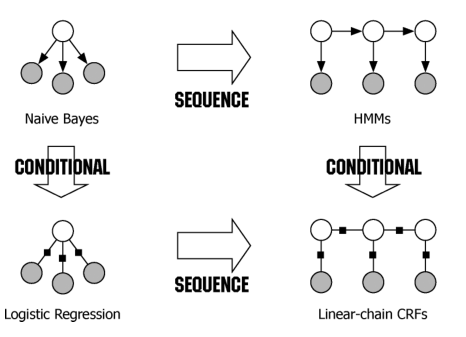
HMM
HMM 模型将标注看作马尔可夫链,一阶马尔可夫链式针对相邻标注的关系进行建模,其中每个标记对应一个概率函数。HMM 是一种生成式模型,定义了联合概率分布 ,其中 x 和 y 分别表示观察序列和相对应的标注序列的随机变量。为了能够定义这种联合概率分布,生成式模型需要枚举出所有可能的观察序列,这在实际运算过程中很困难,因为我们需要将观察序列的元素看做是彼此孤立的个体即假设每个元素彼此独立,任何时刻的观察结果只依赖于该时刻的状态。
HMM 模型的这个假设前提在比较小的数据集上是合适的,但实际上在大量真实语料中观察序列更多的是以一种多重的交互特征形式表现,观察元素之间广泛存在长程相关性。在命名实体识别的任务中,由于实体本身结构所具有的复杂性,利用简单的特征函数往往无法涵盖所有的特性,这时 HMM 的假设前提使得它无法使用复杂特征 (它无法使用多于一个标记的特征)。
MEMM
HMM 与 MEMM 的图模型如下: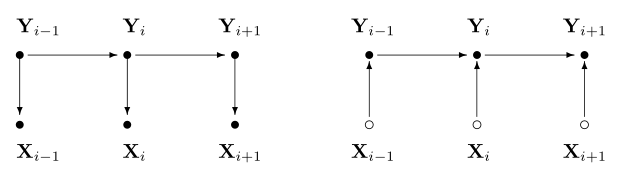
最大熵模型可以使用任意的复杂相关特征,在性能上最大熵分类器超过了 Byaes 分类器。但是,作为一种分类器模型,这两种方法有一个共同的缺点:每个词都是单独进行分类的,标记之间的关系无法得到充分利用,具有马尔可夫链的 HMM 模型可以建立标记之间的马尔可夫关联性,这是最大熵模型所没有的。
最大熵模型的优点:首先,最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型;其次,最大熵统计模型可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度;再次,它还能自然地解决了统计模型中参数平滑的问题。
最大熵模型的不足:首先,最大熵统计模型中二值化特征只是记录特征的出现是否,而文本分类需要知道特征的强度,因此,它在分类方法中不是最优的;其次,由于算法收敛的速度较慢,所以导致最大熵统计模型它的计算代价较大,时空开销大;再次,数据稀疏问题比较严重。
最大熵马尔科夫模型把 HMM 模型和 maximum-entropy 模型的优点集合成一个判别式模型,这个模型允许状态转移概率依赖于序列中彼此之间非独立的特征上,从而将上下文信息引入到模型的学习和识别过程中,提高了识别的精确度,召回率也大大的提高,有实验证明,这个新的模型在序列标注任务上表现的比 HMM 和无状态的最大熵模型要好得多。
CRF
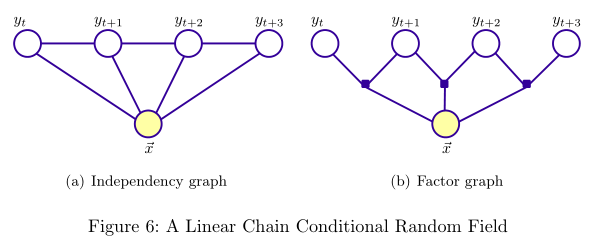
首先,CRF 在给定了观察序列的情况下,对整个的序列的联合概率有一个统一的指数模型。一个比较吸引人的特性是其损失函数 的凸面性。
其次,条件随机域模型相比较改进的隐马尔可夫模型可以更好更多的利用待识别文本中所提供的上下文信息以得更好的实验结果。条件随机域在中文组块识别方面有效,并避免了严格的独立性假设和数据归纳偏置问题。条件随机域 (CRF) 模型应用到了中文名实体识别中,并且根据中文的特点,定义了多种特征模板。并且有测试结果表明:在采用相同特征集合的条件下,条件随机域模型较其他概率模型有更好的性能表现。
再次,词性标注主要面临兼类词消歧以及未知词标注的难题,传统隐马尔科夫方法不易融合新特征,而最大熵马尔科夫模型存在标注偏置等问题。论文引入条件随机域建立词性标注模型,易于融合新的特征,并能解决标注偏置的问题。CRFs 具有很强的推理能力,并且能够使用复杂、有重叠性和非独立的特征进行训练和推理,能够充分地利用上下文信息作为特征,还可以任意地添加其他外部特征,使得模型能够获取的信息非常丰富。同时,CRFs 解决了最大熵模型中的 “label bias” 问题。CRFs 与最大熵模型的本质区别是:最大熵模型在每个状态都有一个概率模型,在每个状态转移时都要进行归一化。如果某个状态只有一个后续状态,那么该状态到后续状态的跳转概率即为 1。这样,不管输入为任何内容,它都向该后续状态跳转。而 CRFs 是在所有的状态上建立一个统一的概率模型,这样在进行归一化时,即使某个状态只有一个后续状态,它到该后续状态的跳转概率也不会为 1,从而解决了 “labelbias” 问题。因此,从理论上讲,CRFs 非常适用于中文的词性标注。
CRF 模型的优点:首先,CRF 模型由于其自身在结合多种特征方面的优势和避免了标记偏置问题。其次,CRF 的性能更好,CRF 对特征的融合能力比较强,对于实例较小的时间类 ME 来说,CRF 的识别效果明显高于 ME 的识别结果。
CRF 模型的不足:首先,通过对基于 CRF 的结合多种特征的方法识别英语命名实体的分析,发现在使用 CRF 方法的过程中,特征的选择和优化是影响结果的关键因素,特征选择问题的好与坏,直接决定了系统性能的高低。其次,训练模型的时间比 ME 更长,且获得的模型很大,在一般的 PC 机上无法运行。
总结
HMM 模型中存在两个假设:一是输出观察值之间严格独立,二是状态的转移过程中当前状态只与前一状态有关 (一阶马尔可夫模型)。HMM 是有向图模型,是生成模型;
MEMM 模型克服了观察值之间严格独立产生的问题,但是由于状态之间的假设理论,使得该模型存在标注偏置问题。MEMM(最大熵马尔科夫模型)是有向图模型,是判别模型;
CRF 模型解决了标注偏置问题,去除了 HMM 中两个不合理的假设,当然,模型相应得也变复杂了。
这三个模型都可以用来做序列标注模型。但是其各自有自身的特点。
- HMM 模型是对转移概率和表现概率直接建模,统计共现概率。
- MEMM 模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率。MEMM 容易陷入局部最优,是因为 MEMM 只在局部做归一化。
- CRF 模型中,统计了全局概率,在做归一化时,考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了 MEMM 中的标记偏置的问题。
视觉问题的应用
- HMMs: 图像去噪、图像纹理分割、模糊图像复原、纹理图像检索、自动目标识别等
- MRF: 图像恢复、图像分割、边缘检测、纹理分析、目标匹配和识别等
- CRF: 目标检测、识别、序列图像中的目标分割

