过拟合
每迭代几次就对模型进行检查它在验证集上的工作情况,并保存每个比以前所有迭代时都要好的模型。此外,还设置最大迭代次数这个限制,超过此值时停止学习。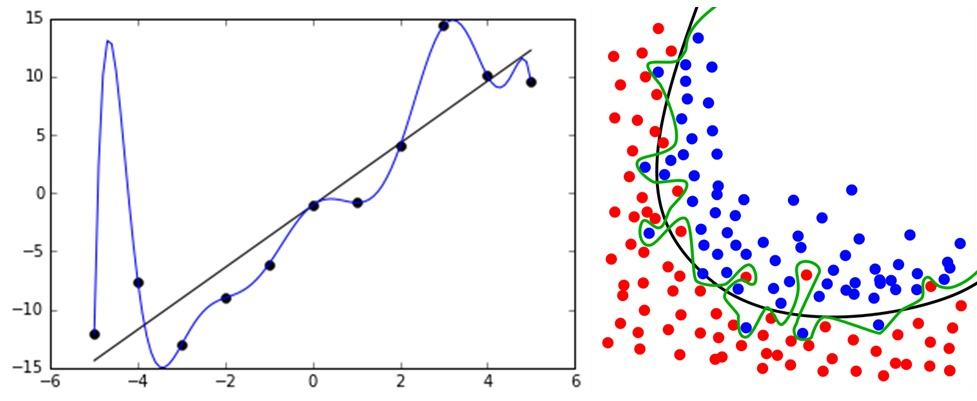
交叉验证
交叉验证的原理为在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用于建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。一般有三种常见形式:简单交叉验证 (Holdout 验证);K 折交叉验证 (K-fold cross-validation);留一验证 (leave-one-out cross validation)。其中 K 折交叉验证又是最常用的一种。
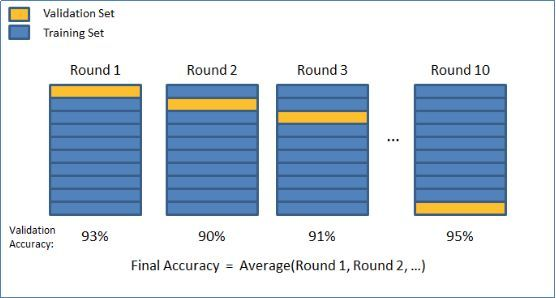
如果交叉验证的结果比单次训练的结果精度下降,就证明了单次分割测试集与训练集出来的结果确实存在过拟合的现象。但缺点也非常明显,速度慢,此外,交叉检验只能起到检验过拟合的作用,并不能抑制过拟合。
增加数据
一种是增加训练样本,第二种是数据增强。
- 在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等。
- 在自然语言处理领域中,可以做同义词替换扩充数据集。
- 语音识别中可以对样本数据添加随机的噪声。
L1 和 L2 正则化
从贝叶斯角度理解最为合理。
Dropout
神经网络的每个单元(属于输出层的那些单元)都被赋予在计算中被暂时忽略的概率 p。超参数 p 称为丢失率,通常将其默认值设置为 0.5。然后,在每次迭代中,根据指定的概率随机选择丢弃的神经元。测试的时候输出乘以概率 p,保证和训练的时候期望一样。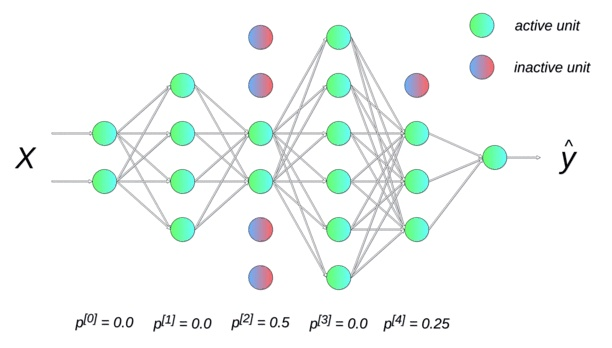
提前停止(early stopping)
每迭代几次就对模型进行检查它在验证集上的工作情况,并保存每个比以前所有迭代时都要好的模型。此外,还设置最大迭代次数这个限制,超过此值时停止学习。缺点在于需要额外的空间,而且不好和其他的参数一起调。
结合多种模型
训练多个模型,以每个模型的平均输出作为结果。
- Bagging:多个强模型的输出平均,是并行的
- Boosting:多个弱模型的递进学习,增加前面学习器没有学习好的样本的权重,是串行的
剪枝
剪枝是决策树类算法防止过拟合的方法。如果决策树的结构过于复杂,可能会导致过拟合问题,此时需要对树进行剪枝,消掉某些节点让它变得更简单。剪枝的关键问题是确定减掉哪些树节点以及减掉它们之后如何进行节点合并。决策树的剪枝算法可以分为两类,分别称为预剪枝和后剪枝。
- 预剪枝在树的训练过程中通过停止分裂对树的规模进行限制
- 后剪枝先构造出一棵完整的树,然后通过某种规则消除掉部分节点,用叶子节点替代。
多任务学习
深度学习中两种多任务学习模式:隐层参数的硬共享和软共享
- 硬共享机制是指在所有任务中共享隐藏层,同时保留几个特定任务的输出层来实现。硬共享机制降低了过拟合的风险。多个任务同时学习,模型就越能捕捉到多个任务的同一表示,从而导致模型在原始任务上的过拟合风险越小。
- 软共享机制是指每个任务有自己的模型,自己的参数。模型参数之间的距离是正则化的,以便保障参数相似性。
- 特征选择,减少特征数或使用较少的特征组合
- 交叉检验,通过交叉检验得到较优的模型参数
BN
比较有争议。按照这篇文章说的,可能在一些情况下有抑制作用,使得 overfitting 再更多的 training epoch 后出现,但并不能阻止。
Batch Normalization(以下称 BN)的主要作用是加快网络的训练速度。
硬要说是防止过拟合,可以这样理解:BN 每次的 mini-batch 的数据都不一样,但是每次的 mini-batch 的数据都会对 moving mean 和 moving variance 产生作用,可以认为是引入了噪声,这就可以认为是进行了 data augmentation,而 data augmentation 被认为是防止过拟合的一种方法。因此,可以认为用 BN 可以防止过拟合。

