本文主要是对网上的一些文章的总结,参考的文章在文末已经列出
音频信号是模拟信号,我们需要将其保存为数字信号,才能对语音进行算法操作,WAV 是 Microsoft 开发的一种声音文件格式,通常被用来保存未压缩的声音数据。
语音信号有三个重要的参数:声道数、取样频率和量化位数。
- 声道数:可以是单声道或者是双声道
- 采样频率:一秒内对声音信号的采集次数,44100Hz 采样频率意味着每秒钟信号被分解成 44100 份,如果采样率高,那么媒体播放音频时会感觉信号是连续的。
- 量化位数:用多少 bit 表达一次采样所采集的数据,通常有 8bit、16bit、24bit 和 32bit 等几种
如果你需要自己录制和编辑声音文件,推荐使用 Audacity (http://audacity.sourceforge.net), 它是一款开源的、跨平台、多声道的录音编辑软件。
音频信号读取
1 | from scipy.io import wavfile |
音频的时域信号波形: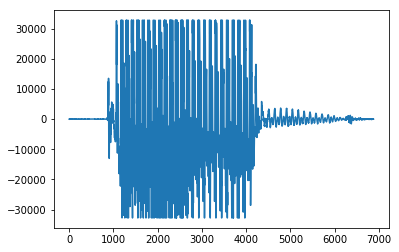
语音信号是一个非平稳的时变信号,但语音信号是由声门的激励脉冲通过声道形成的,而声道 (人的口腔、鼻腔) 的肌肉运动是缓慢的,所以 “短时间”(10-30ms) 内可以认为语音信号是平稳时不变的。由此构成了语音信号的 “短时分析技术”。
在短时分析中,将语音信号分为一段一段的语音帧,每一帧一般取 10-30ms,我们的研究就建立在每一帧的语音特征分析上。
提取的不同的语音特征参数对应着不同的语音信号分析方法:时域分析、频域分析、倒谱域分析… 由于语音信号最重要的感知特性反映在功率谱上,而相位变化只起到很小的作用,所有语音频域分析更加重要。
预加重
预增强以帧为单位进行,目的在于加强高频。去除口唇辐射的影响,增加语音的高频分辨率。因为高频端大约在 800Hz 以上按 6dB/oct (倍频程) 衰减,频率越高相应的成分越小,为此要在对语音信号进行分析之前对其高频部分加以提升,也可以改善高频信噪比。k 是预增强系数,常用 0.97。
1 | pre_emphasis = 0.97 |
分帧
分帧是将不定长的音频切分成固定长度的小段。为了避免窗边界对信号的遗漏,因此对帧做偏移时候,帧间要有帧移 (帧与帧之间需要重叠一部分),帧长 (wlen) = 重叠 (overlap)+ 帧移 (inc)。inc 为帧移,表示后一帧第前一帧的偏移量,fs 表示采样率,fn 表示一段语音信号的分帧数。
通常的选择是帧长 25ms(下图绿色),帧移为 10ms(下图黄色)。接下来的操作是对单帧进行的。要分帧是因为语音信号是快速变化的,而傅里叶变换适用于分析平稳的信号。帧和帧之间的时间差常常取为 10ms,这样帧与帧之间会有重叠(下图红色),否则,由于帧与帧连接处的信号会因为加窗而被弱化,这部分的信息就丢失了。
语音信号的短时频域处理
在语音信号处理中,在语音信号处理中,信号在频域或其他变换域上的分析处理占重要的位置,在频域上研究语音可以使信号在时域上无法表现出来的某些特征变得十分明显,一个音频信号的本质是由其频率内容决定的,将时域信号转换为频域信号一般对语音进行短时傅里叶变换。
python_speech_features
python_speech_features 的比较好用的地方就是自带预加重参数,只需要设定 preemph 的值,就可以对语音信号进行预加重,增强高频信号。
python_speech_features 模块提供的函数主要包括两个:MFCC 和 FBank。API 定义如下:
python_speech_features.base.fbank(signal, samplerate=16000, winlen=0.025, winstep=0.01, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97, winfunc=
>)
从一个音频信号中计算梅尔滤波器能量特征,返回:2 个值。第一个是一个包含着特征的大小为 nfilt 的 numpy 数组,每一行都有一个特征向量。第二个返回值是每一帧的能量。
python_speech_features.base.logfbank(signal, samplerate=16000, winlen=0.025, winstep=0.01, nfilt=26, nfft=512, lowfreq=0, highfreq=None, preemph=0.97)
从一个音频信号中计算梅尔滤波器能量特征的对数,返回: 一个包含特征的大小为 nfilt 的 numpy 数组,每一行都有一个特征向量
参数
1 | 参数: |
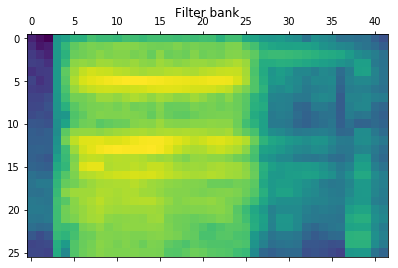
MFCC 特征和过滤器特征
1 | from python_speech_features import mfcc, logfbank |
输出如下:
1 | MFCC: |

触发词检测

Reference
- https://jingyan.baidu.com/article/1709ad804e575b4634c4f0b1.html
- https://zhuanlan.zhihu.com/p/57004884
- https://python-speech-features.readthedocs.io/en/latest/
- https://www.meiwen.com.cn/subject/ahyxuqtx.html
- https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
- https://www.cnblogs.com/LXP-Never/p/10078200.html#%E9%9F%B3%E9%A2%91%E4%BF%A1%E5%8F%B7%E7%9A%84%E8%AF%BB%E5%86%99%E3%80%81%E6%92%AD%E6%94%BE%E5%8F%8A%E5%BD%95%E9%9F%B3
- https://github.com/majianjia/nnom/tree/master/examples/keyword_spotting

