哈希函数
哈希函数又叫散列函数,输入范围很大,输出范围固定。
哈希函数的性质:
- 无限的输入域
- 输出值相同时,返回值一样
- 输入值不同时,返回值可能一样,也可能不一样
- 不同的输入值得到的 hash, 整体均匀分布在输出域上
1~3 是哈希函数的基础,第四点是评价 hash 函数优劣的关键。
Map-Reduce
- map 阶段:把大任务分解为子任务
- reduce 阶段:子任务并发处理然后合并结果
注意点:
- 数据备份和容灾(需要多少备份)
- 任务分配策略和任务进度跟踪
- 多用户权限的控制
Map-Reduce 统计文章单词出现的个数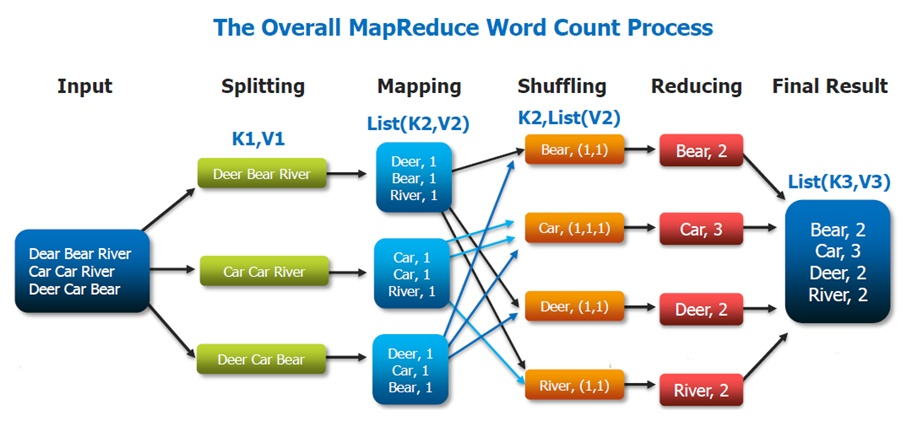
一致性 hash
数据的归属问题:数据经过 hash 计算到环上,如果在中间顺时针到离它最近的机器上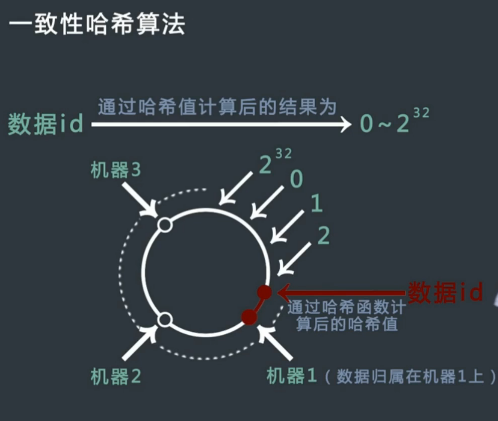
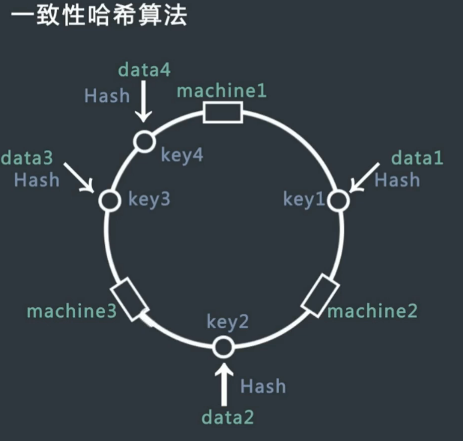
例如上图:data1 归属于 machine2,data3 归属于 machine3,data3、data4 归属于 machine1
机器的添加和删除: 一个机器故障,数据顺时针迁移到下一台机器上。添加新的机器的时候添加机器和它逆时针的最近机器之间的数据迁移到添加机器上。
常见海量处理题目的关键
- 分而治之:通过 hash 函数把大任务分流到机器,或者分流成小文件
- 常用 hashMap 或者 bitMap 上面
难点在对通讯、时间、空间复杂度的估计
IPV4 地址排序
请对 10 亿个 IPV4 地址排序,每个 ip 出现一次
方法:BitMap: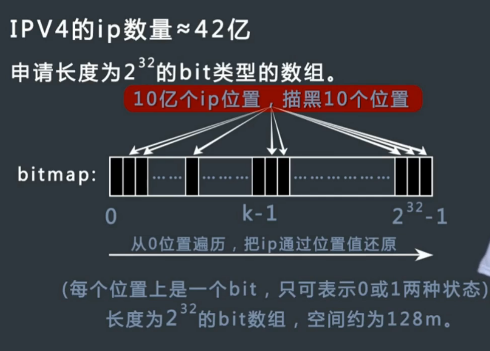
年龄排序
10 亿人的年龄排序
方法:计数排序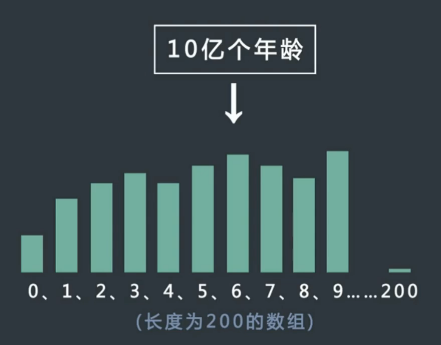
出现内存中最多的数
有一个包含 20 亿个全是 32 位整数的大文件,在其中找到出现次数最多的数。但是内存限制只有 2G.
哈希表方案(不可行):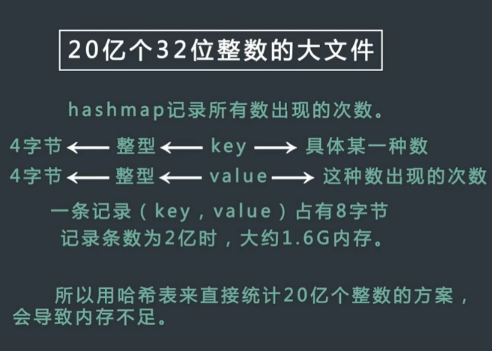
哈希分流 (可行):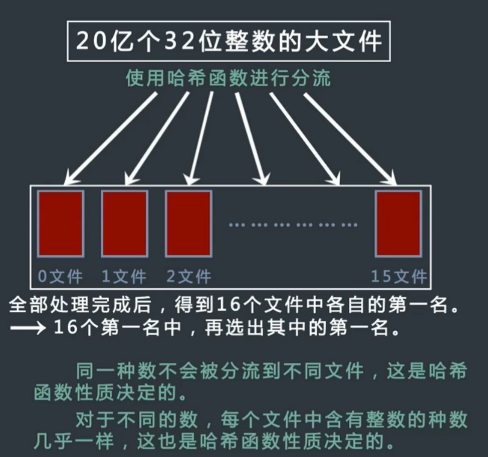
计算:8 字节 x2 亿 = 1.6G
没出现过的数
32 位无符号整数的范围是 0~4294967295。现在有一个正好包含 40 亿个无符号整数的文件,所以在整个范围中必然有没出现过的数。可以使用最多 10M 的内存,
只用找到一个没出现过的数即可,该如何找?
hashMap 方法(不可行):
bitMap 方法(不可行):
hash 分流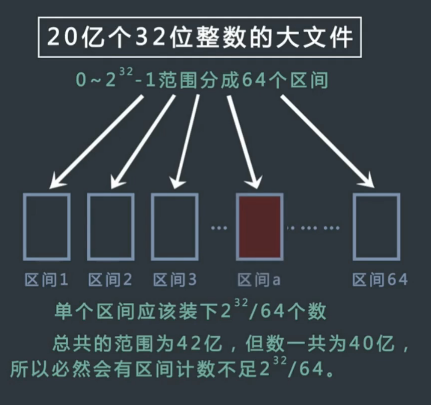

热词 Topk
百亿数据量的搜索词汇,设计求每天最热 100 词的方法
hash 分流

