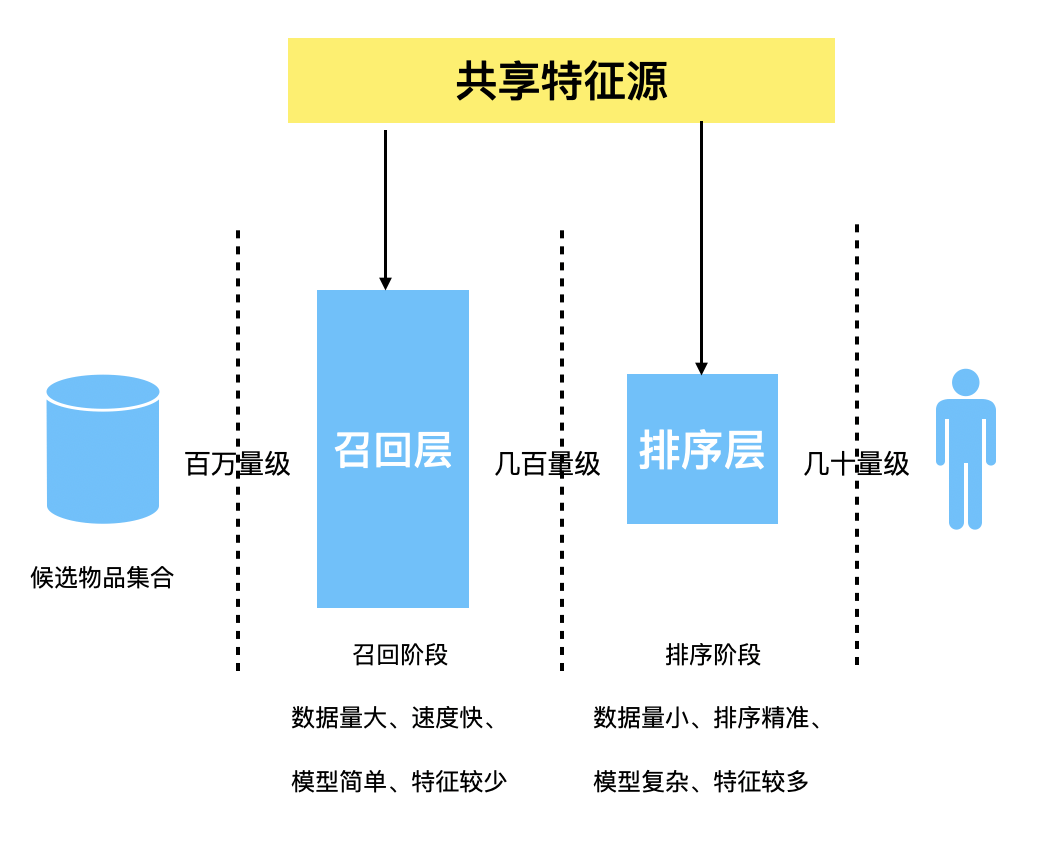
在推荐系统众多方法中,基于用户的协同过滤推荐算法是最早诞生的,原理也较为简单。该算法 1992 年提出并用于邮件过滤系统,两年后 1994 年被 GroupLens 用于新闻过滤。一直到 2000 年,该算法都是推荐系统领域最著名的算法。
基本思想
核心思想:相似的用户可能喜欢相同物品。当一个用户 A 需要个性化推荐时,可以先找到和他兴趣相似的用户群体 B,然后把 B 喜欢的、并且 A 没有听说过的物品推荐给 A,这就是基于用户的协同过滤算法。
实现步骤
- 找到与目标用户兴趣相似的用户集合
- 找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户
发现兴趣相似的用户
协同过滤算法主要利用行为的相似度计算兴趣的相似度。
获得数据
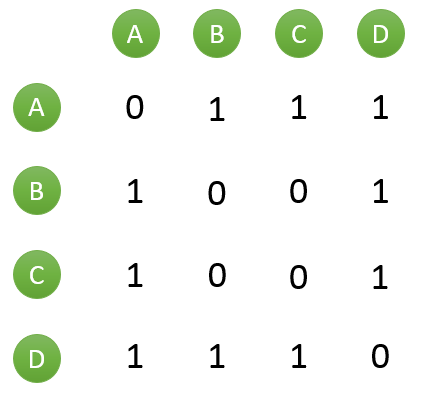
假设目前共有 4 个用户: A、B、C、D;共有 5 个物品:a、b、c、d、e。用户与物品的关系(用户喜欢物品)如下图所示:

构建倒排表
建立 “物品 — 用户” 的倒排表

构建用户相似度矩阵
构建用户相似度矩阵 matrix,其中 matrix [A][B] 表示用户 A 和用户 B 共同喜欢的电影的数量。
计算用户相似度

基于热度惩罚的用户相似度改进
生成推荐
评测指标
对用户 $u$ 推荐 $N$ 个物品 (记为 $R (u)$ ),令用户 $u$ 在测试集上喜欢的物品集合为 $T (u)$ ,然后可以通过准确率、召回率、覆盖率评测推荐算法的精度:
召回率
准确率
覆盖率
覆盖率反映了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给用户。
分子部分表示实验中所有被推荐给用户的物品数目 (集合去重),分母表示数据集中所有物品的数目。

